
Redis Streams, inspirado en Apache Kafka, es una solución de mensajería para sistemas distribuidos donde los datos llegan continuamente, son almacenados (ofrece persistencia), y procesados en tiempo real con garantía de entrega y de procesamiento, como ocurre en entornos de IoT y Big Data. Un Stream es un conjunto de mensajes o eventos temporales, que pueden llegar de forma masiva (gran volumen) y a gran velocidad. Puede trabajarse con uno o varios Streams, con múltiples Productores (ej: sensores IoT o microservicios comunicándose asíncronamente), y múltiples Grupos de Consumidores (ej: cálculos en tiempo real, descarga a Data Lake o Data Warehouse, etc), para formar un sistema escalable y tolerante ante fallos.
Continuando con nuestra serie sobre Redis, ahora que ya hemos hablado (entre otras cosas) sobre las diferentes estructuras de datos que soporta Redis (Strings, Hashes, Lists, Sets, y Sorted Sets), del problema y posibles soluciones de la búsqueda sobre claves en función de sus Atributos, de las Transacciones en Redis, y del mecanismo de Publicación y Suscripción que proporciona Redis, llega el momento de hablar de Redis Streams.
Redis Streams, disponible desde Redis 5, es un nuevo tipo de dato o estructura de datos, que actua como una lista o log de tipo append-only (similar a una cola), que almacena mensajes o eventos, a los que podemos acceder a través de su clave (key) y un ID de mensaje (hay más detalles, como primera introducción, vale). Podemos ejecutar comandos como DEL ó EXPIRE, como con cualquier otra clave, así como comandos específicos para trabajar con Streams (suelen estar prefijados con una X como XADD, XLEN, XTRIM, etc.).
Cada mensaje de un Stream tiene un ID único e inmutable (habitualmente con un prefijo timestamp con precisión de milisegundos, seguido de un número de secuencia que garantiza unicidad, permitiendo consultas temporales basadas en rangos, y un indexamiento temporal) y están formadas por parejas de clave-valor (similar a los hashes). Este ID único puede gestionarse de dos formas:
- Puede generarse automáticamente por Redis especificando como argumento un *, garantizando su unicidad y orden creciente de creación, de una forma sencilla (método recomendado), basándose en un timestamp con precisión de milisegundos seguido de un número de secuencia (para que en situaciones de varios registros creados en el mismo milisegundo, poder garantizar su unicidad).
- Puede pasarse como argumento el ID que se desea utilizar para crear el mensaje o evento, lo que transmite la responsabilidad de garantizar su unicidad y orden incremental de creación a los Productores, aumentando la complejidad (no recomendado, aunque puede haber casos de uso que encajen muy bien así).
Para comprender mejor todo esto, lo mejor es hacer alguna prueba, como por ejemplo ejecutar los siguientes comandos a través de una sesión de redis-cli.
xadd iot:temp:sensors * celsius 34 location mad-01
xadd iot:temp:sensors * celsius 33 location mad-02
xlen iot:temp:sensors
9 xadd iot:temp:sensors * celsius 31 location mad-04
xadd iot:humedity:sensors 20221001 humidity 54 location mad-01
xadd iot:humedity:sensors 20221002 humidity 57 location mad-01
xadd iot:humedity:sensors 20221003 humidity 56 location mad-01
xadd iot:wind:sensors 20221001-1 wind 14 location mad-01
xadd iot:wind:sensors 20221001-2 wind 17 location mad-02
xadd iot:wind:sensors 20221001-3 wind 21 location mad-03
A continuación se muestra la salida de ejecución de los anteriores comandos.
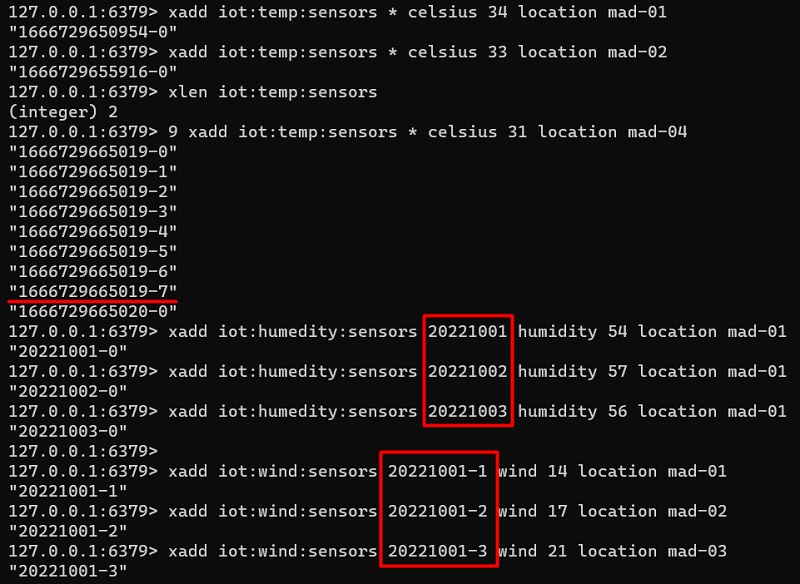
Los mensajes son creados por los Productores, almacenados en la memoria de Redis (proporcionando buffering, que a su vez permite persistencia y durabilidad), y procesados por los consumidores (habitualmente en orden, desde los mensajes más antiguos a los más recientes), ya sea por rangos o uno a uno.
Los Productores, que a modo ilustrativo podrían ser miles de sensores IoT (ej: temperatura, humedad, velocidad del viento, etc) o los diferentes microservicios del Backend de una Aplicación comunicándose de forma asíncrona, utilizaran principalmente el comando XADD para enviar mensajes y el comando XLEN para obtener el número de mensajes que hay en una clave. Si fuera necesario, también podrían utilizar el comando XDEL para eliminar uno o varios mensajes de una clave o Stream (el comando DEL o UNLINK eliminaría la clave o Stream completo). Un detalle importante, es que en una misma clave o Stream, los mensajes no tienen porque mantener el mismo esquema, al igual que ocurre con otros tipos de datos en Redis: podríamos tener dos mensajes con campos totalmente distinto, o con unos campos comunes y otros no, y no pasa nada, úsalo según lo necesites.
Podemos tener varios Consumidores, cada uno de los cuales es capaz de procesar el Stream completo (similar a un suscriptor en Pub/Sub), lo que permite que todos los eventos de nuestro Stream puedan ser procesados/enviados por separado múltiples veces (ej: hacer un cálculo en real-time, enviar al Data Lake, a un servicio de notificación, y a un pipeline de Machine Learning).
Sin embargo, al contrario que ocurre con el mecanismo de Publicación y Suscripción de Redis (que no ofrece buffering, es decir, no almacena los mensajes en memoria, comportándose como un canal efímero, donde el suscriptor debe estar conectado para poder recibir los mensajes), los Streams se almacenan en memoria como cualquier otro tipo de dato de Redis (proporcionando buffering, persistencia y durabilidad), por lo que si un consumidor no está conectado durante un periodo de tiempo, podrá recuperar después los mensajes que no ha leído garantizando su entrega y procesamiento. Incluso puede haber varios consumidores, y todos ellos procesar todos los mensajes, al estar almacenados, accesibles, y disponibles para todos. Hay más diferencias entre Pub/Sub y Streams, por ejemplo Pub/Sub se basa en Strings mientras que Streams es una estructura similar a un Hash, y además Pub/Sub no tiene IDs en sus mensajes.
Podemos consultar los mensajes de una clave o Stream con el comando XRANGE (o también podríamos utilizar el comando XREVRANGE, idéntico pero en orden inverso), indicando un rango delimitado por el ID menor y el mayor (ambos estarán inclusives en la respueta) por los que queremos consultar (o los símbolos – y + para seleccionar el primero y el último), pudiendo utilización la opción COUNT para hacerlo paginando y poder ir iterando (batch processing), importante cuando hay gran cantidad de mensajes, y especialmente cuando se accede de forma programática. Así, si quiesiéramos obtener un único elemente, utilizaríamos el comando XRANGE o XREVRANGE con el la opción COUNT 1, y listo, teniendo en cuenta que XRANGE y XREVRANGE permiten leer mensajes de la clave sin borrarlos, por lo que siguen estando disponibles para que otros consumidores los puedan leer.
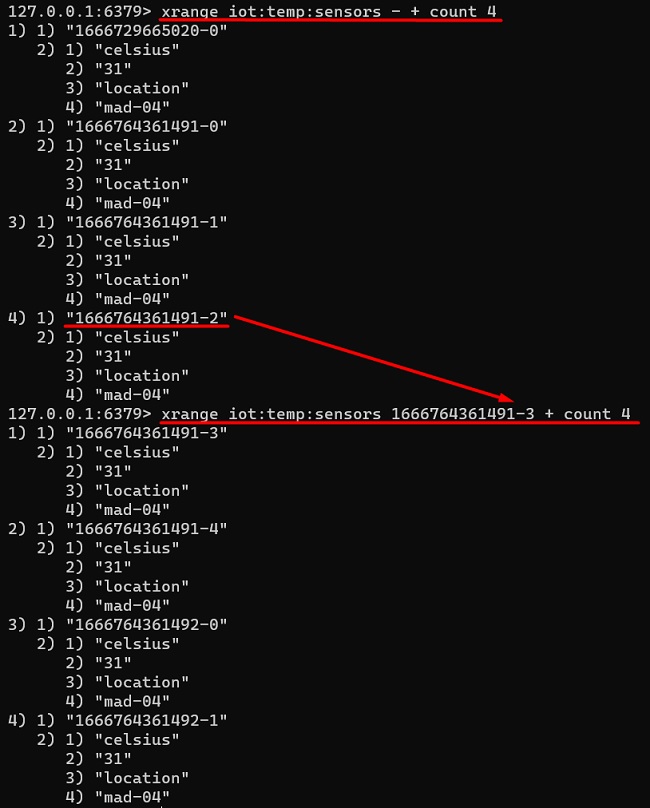
Podemos truncar un Stream con el comando XTRIM, lo que permitiría mantener sólo los N últimos mensajes (más reciente) o mantener los elementos desde un mensaje (ID) determinado, y eliminar el resto (más antiguos) liberando memoria, y evitando que nuestro Stream crezca indefinidamente hasta ocupar toda la memoria del servidor (esto acabaría mal seguro). También podemos utilizar la tilde con MAXLEN (opción recomendada), para mantener aproximadamente los N últimos mensajes, al ser una operación más eficiente, aunque no estrictamente exacta. Más abajo vemos en más detalle las diferentes estrategias de truncado.
A continuación se muestran algunos comandos de ejemplo.
xrange iot:temp:sensors - +
xrevrange iot:temp:sensors + -
xrange iot:temp:sensors 1666729665021 1666764361492
xrange iot:temp:sensors 1666729665021-0 1666764361492-3
xrange iot:temp:sensors - + count 5
xrange iot:temp:sensors - + count 1
xrevrange iot:temp:sensors + - count 1
xlen iot:temp:sensors
xtrim iot:temp:sensors maxlen 10
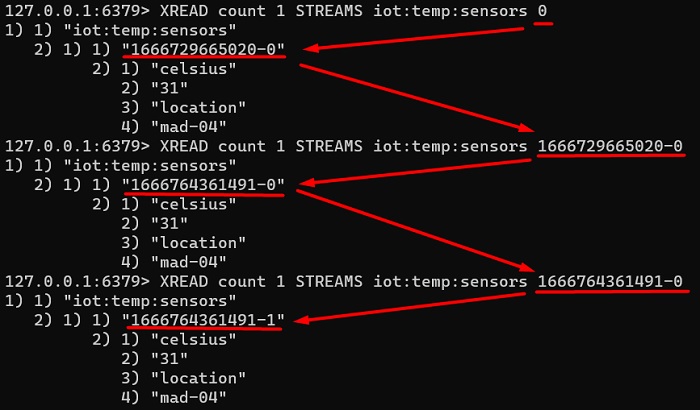
xlen iot:temp:sensorsTambien tenemos el comando XREAD (similar a XRANGE) que permite que un consumidor pase como argumento el ID del último mensaje que conoce (no se pasa un rango como con XRANGE) de uno o varios Streams, y devuelve los mensajes más recientes a partir del mismo (es decir, es exclusivo, la respuesta no incluirá el mensaje indicado, sólo los posteriores), que podemos paginar con la opción COUNT. Si queremos leer todos los mensajes, podemos pasar como ID 0 ó 0-0, y listo.
De forma similar a como ocurre con las Listas en Redis (comandos LPOP y BLPOP), al leer de Stream podemos hacerlo bloqueando (quedando a la espera de que llege un mensaje) o sin bloquear (leer devolviendo inmediatamente el valor, o nil en su ausencia).
XREAD permite utilizar la opción BLOCK para leer en modo bloqueo (es decir, quedándose a la espera si no está el mensaje que esperamos), con un tiempo de timeout (cero significa esperar para siempre, lo cual no es recomendable), de tal modo que si se cumple el timeout y no ha llegado el mensaje que se esperaba, se finaliza devolviendo nil.
Si lo que necesitamos, es leer el próximo mensaje que va a llegar quedando en espera (modo bloqueo), podemos utilizar el $ como ID del mensaje (ej: XREAD block 0 streams iot:temp:sensors $).
Es posible tener varios consumidores escuchando en modo bloqueo con XREAD (ej: XREAD block 0 streams iot:temp:sensors $), de tal modo, que cada consumidor leerá todos los nuevos mensajes, trabajando en paralelo, lo que en algunos casos podría proporcionar cierto nivel de escalabilidad, al permitir diferentes consumidores que tengan que realizar tareas distintas.
A continuación se muestran algunos compandos de ejemplo.
XREAD STREAMS iot:temp:sensors 1666765123843-5
XREAD STREAMS iot:temp:sensors 0
XREAD count 1 block 2000 streams iot:temp:sensors 1666765123843-8
XREAD block 0 streams iot:temp:sensors $
XREAD block 0 streams iot:temp:sensors 1666765123843-8A continuación se muestra un pantallazo con un ejemplo de uso de XREAD, en modo sin bloqueo, para iterar por los mensajes de una clave.
Otro detalle importante con los Streams, es que aunque cada mensaje es similar a un Hash, el Stream sólo se puede recuperar de forma completa, es decir, no se puede recuperar sólo una de sus propiedades o campos, tiene que ser el mensaje completo, con todos sus campos.
La mayoría de las estructuras de datos en Redis son mutables (se puede cambiar su contenido a lo largo del tiempo, después de su creación, o en el caso de las Listas, podemos añadir elementos a mitad de la misma). Sin embargo, los Streams no son mutables, aunque permiten un par excepciones, ya que es posible el borrado de elementos (comando XDEL) y el recorte (comando XTRIM) de un Stream para dejar únicamente los más recientes (similar a las Listas con el comando LTRIM).
Entornos escalables de Alta Concurrencia: Consume Groups
En entornos de Alta Concurrencia, el Productor podría crear mensajes a una velocidad mayor de la que un único Consumidor es capaz de procesarlos. En este caso, usando múltiples Consumidores no lo resolveríamos (al contrario, haríamos un problema más grande), ya que todos los Consumidores recibirían los mismos datos. Necesitamos un patrón escalable orientado a eventos.
Una posible solución es Particionar utilizando múltiples claves o Streams con un Consumidor para cada clave o Stream, de tal modo que el Productor vaya creando los mensajes repartiéndolos entre una u otra clave, para así repartir la carga entre los Consumidores. El inconveniente de este modelo, es que un cambio en el particionamiento, para añadir o quitar claves y consumidores, no es nada dinámico, resultando en una tarea no trivial que requiere de cierto esfuerzo, aunque ofrece la bondad de que con Redis Cluster las diferentes claves o Streams se podrían repartir entre los diferntes nodos, mejorando el rendimiento. No es una solución escalable.
La solución definitiva es el uso de uno o varios Consumer Groups, cada uno de los cuales puede estar formado por uno o varios Consumidores y es capaz de procesar el Stream completo (cada Consumidor de cada Consumer Group procesará sólo una porción o subconjunto de mensajes), lo que permite que todos los eventos de nuestro Stream puedan ser procesados/enviados por separado múltiples veces por los diferentes Consume Groups que a la vez repartirán la carga en uno o varios Consumidores (ej: enviar al Data Lake, a servicio de notificación, y a un pipeline de Machine Learning). Un Consumer Group es conceptualmente una cola asociada a un Stream, sobre la que varios consumidores son capaces de procesar los mensajes, lo que permite añadir o quitar Consumidores de un Consumer Group de forma fácil y dinámica, para así poder escalar nuestra capacidad de procesamiento de forma distribuida.
- Para crear un Consumer Group en un Stream existente utilizaremos el comando XGROUP CREATE, especificando la clave del Stream, el nombre del grupo, y el ID del mensaje desde el que se quiere que empiecen a procesar sus consumidores (podemos indicar 0 ó 0-0 para comenzar desde el principio, o $ para comenzar desde el próximo mensaje). Si el Stream no existe aún, deberemos utilizar la opción MKSTREAM.
- Para obtener los mensages de un Consume Group para procesarlos, utilizaremos el comando XREADGROUP (en lugar de XREAD), especificando el grupo, la clave y un nombre del consumidor, además de las opciones COUNT y BLOCK si así lo deseamos. El símbolo «>» significa que solicitamos el siguiente mensaje que no ha sido aún entregado a ningún otro consumidor.
- Después de leer y de procear un mensaje, debemos confirmar su procesamiento con el comando XACK especificando la clave, el grupo y el ID de uno o varios mensajes. Esto nos da la capacidad, de que si perdemos un consumidor a mitad del procesamiento de un mensaje, podamos identificar los mensajes leidos no confirmados para poder reprocesarlos correctamente, y así tener garantía de entrega y de procesamiento, que en muchos casos es fundamental (Redis almacena y mantiene para cada Stream una lista de entradas pendientes: PEL). Si no deseamos usar confirmaciones, podemos crear los mensages con la opción NOACK del comando XREADGROUP.
- Podemos utilizar el comando XINFO GROUPS para obtener información de los Consumer Groups creados sobre una clave, como por ejemplo:.
- ID del último mensaje entregado a un consumidor (last-entry-id).
- Cuántos mensajes hay pendientes (pending), es decir, que han sido leídos pero no confirmados (ACK). Idealmente debería ser cero, o un valor muy cercano a cero.
- Cuántos consumidores hay en el grupo.
- Si el consumidor falla y se reinicia, podría volver a procesar todos los mensajes no confirmados con el comando XREADGROUP comenzando desde el ID 0, tras lo cual, podrá procesar los nuevos mensajes especificando el símbolo «>». De este modo, se consigue garantizar que no se quedan mensajes sin procesar.
- Podemos utilizar el comando XINFO CONSUMERS para obtener información de los diferentes Consumidores de un Grupo de Consumidores de una clave o Stream, como por ejemplo, cuántos mensajes tiene pendiente de confirmar (debería ser cero).
A continuación se muestran algunos comandos de ejemplo.
xgroup create test-stream datalake-group 0 MKSTREAM
exists test-stream
xlen test-stream
xgroup create iot:temp:sensors datalake-group-all 0
xgroup create iot:temp:sensors datalake-group-new $
xinfo groups iot:temp:sensors
xreadgroup group datalake-group-all consumer-01 count 1 block 2000 STREAMS iot:temp:sensors >
xack iot:temp:sensors datalake-group-all 1666764361491-3
xinfo groups iot:temp:sensors
xreadgroup group datalake-group-all consumer-02 count 1 block 2000 STREAMS iot:temp:sensors >
xack iot:temp:sensors datalake-group-all 1666764361491-4
xinfo consumers iot:temp:sensors datalake-group-allEl uso de Consumer Groups nos ofrece una gran potencia y versatilidad, además de la garantía de entrega y de procesamiento, pero también añade más complejidad e implica que podemos necesitar realizar algunas tareas de mantenimiento como las siguientes (no deberían ser muy habituales, pero en alguna ocasión las podemos necesitar).
- Cambiar la posición de un Consumer Group en un Stream, es decir, el ID del último mensaje entregado a un consumidor (last-entry-id del comando XINFO GROUPS). Para esto podemos utilizar el comando XGROUP SETID.
- Eliminar un Consumer Group, para lo que podemos utilizar el comando XGROUP DESTROY.
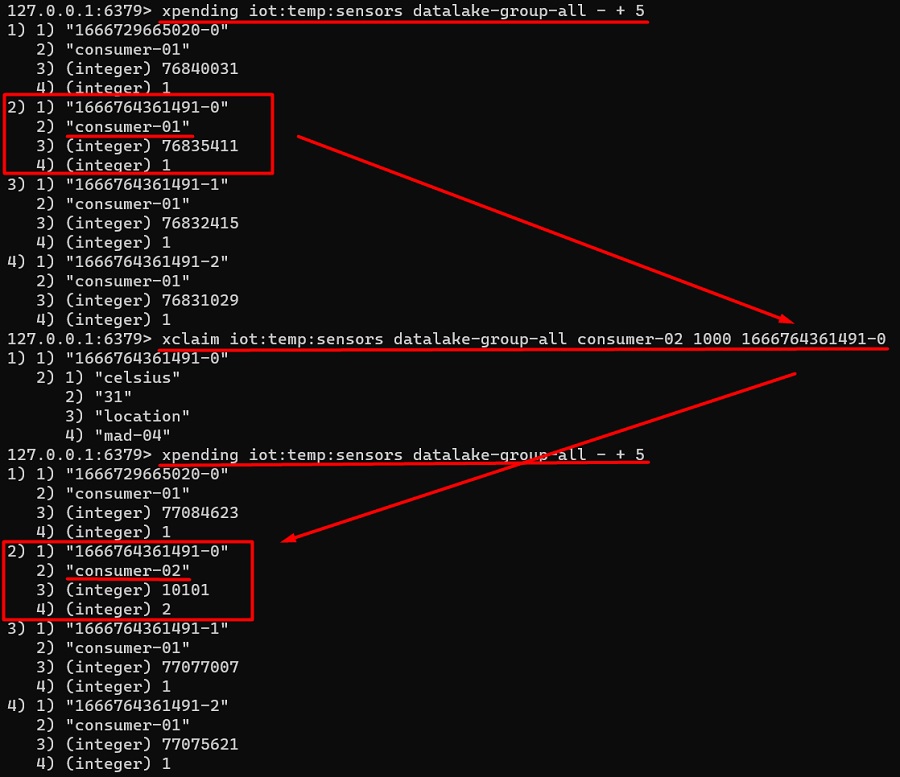
- Eliminar un Consumidor concreto de un Consumer Group, para lo que podemos utilizar el comando XGROUP DELCONSUMER. Es importante comprobar antes si el Consumidor tiene mensajes pendientes (que han sido leídos pero no confirmados – ACK), para evitar eliminar el consumidor dejando mensajes que no se han procesado, y así garantizar la entrega y procesamiento de los mismos. En caso de existir mensajes pendientes, es posible reasignarlos con el comando XPENDING (muestra los mensajes pendientes de confirmación) y el comando XCLAIM (permite asignar un mensaje a otro Consumidor, es decir, cambiar su Onwnership).
A continuación se muestran algunos comandos de ejemplo.
xgroup setid iot:temp:sensors 0
xgroup setid iot:temp:sensors 1666764361491-4
xgroup setid iot:temp:sensors $
xpending iot:temp:sensors datalake-group-all
xpending iot:temp:sensors datalake-group-all - + 5
xclaim iot:temp:sensors datalake-group-all consumer-02 1000 1666764361491-0A continuación se muestra un ejemplo del uso de XPENDING y XCLAIM, para listar los mensajes pendientes y cambiar de Owner (es decir, de Consumidor), uno de los mensajes.
Un mensaje poison-pill es aquel que siendo posible leerlo, nunca es posible llegar a procesarlo (nunca se consigue el ACK), acabando siempre en Pending, incluso podría llegar a finalizar la ejecución del Consumidor (provocar un crash). La forma de solucionar este tipo de situaciones, es borrando el mensaje (XDEL) o incluso confirmándolo (XACK) aún sabiendo que no ha sido procesado, con el fin de acabar de este bucle infinito, apartandi dicho mensaje del conjunto de mensajes pendientes (PEL).
Estrategias de Truncado
Con Redis Streams, los mensajes son almacenados en memoria, por lo tanto, según va pasando y pasando el tiempo, mientras los Productores y Consumidores siguen escribiendo y leyendo mensajes, la memoria de Redis sigue y sigue aumentando, lo que puede producir que se alcance su tamaño máximo si no tomamos medidas (antes o después, es sólo cuestión de tiempo), y ya no podamos escribir más mensajes.
Para evitar que lleguemos a esta situación, tenemos varias alternativas, cada una con sus ventajas e inconvenientes.
- Truncar el Stream cada vez que se añade un mensaje nuevo con XADD. Tan sencillo como utilizar la opción MAXLEN del comando XADD, y listo. Con esto, cada vez que añadimos un mensaje, nos aseguramos de dejar sólo las N últimos (ej: MAXLEN 1000). También podemos utilizar la tilde con MAXLEN (opción recomendada), para mantener aproximadamente los N últimos mensajes, al ser una operación más eficiente (ej: MAXLEN ~ 1000).
- Truncar el Stream periódicamente con XTRIM. Básicamente consiste en ejecutar un comando XTRIM de forma periódica, a poder ser utilizando la tilde con MAXLEN, para optimizar el uso de recursos. En este caso, probablemente necesitemos un proceso adicional, que no sea ni un productor ni un consumidor, que realice este truncado de forma periódica, quizás planificado como un CRON.
- Truncar el Stream en base a Particiones (claves). Podemos particionar nuestro Stream utilizando varios Streams (es decir, varias claves), según el criterio que nos interese, que además tiene ventajas de rendimiento si usamos un Redis Cluster, ya que las claves de distribuyen entre todos los nodos (Shards). Por ejemplo, podríamos utilizar una clave para cada día (ej: iot:temp:sensors:20221027) o para cada mes (ej: iot:temp:sensors:202210), y utilizar el comando EXPIRE para hacerlas expirar automáticamente o bien eliminar manualmente las claves antiguas (comando DEL).
A continuación se muestran algunos comandos de ejemplo, a nivel ilustrativo.
xlen iot:temp:sensors
xadd iot:temp:sensors MAXLEN 1000 * celsius 34 location mad-01
xadd iot:temp:sensors MAXLEN ~ 1000 * celsius 34 location mad-01
xtrim iot:temp:sensors maxlen ~ 1000
DEL iot:temp:sensors:202210Algunas consideraciones de Diseño
Hay más tips a tener en cuenta al trabajar con Redis Streams, además de todo lo que ya hemos hablado a lo largo de este Post, como por ejemplo:
- Mensajes grandes (large pay-load). El problema es que si hay muchos podríamos alcanzar el límite de memoria del servidor Redis, ya que una clave tiene que estar almacenada en un único servidor. Utilizando un Cluster de Redis, las claves se distribuyen entre los diferententes nodos (Shards), pero si toda la info está en la misma clave, esto no aliviará. Una solución es almacenar los datos fuera del Stream (en el Stream los referenciaríamos), quedando almacenados en otras claves de Redis (ej: Redis Hash, que se podría distribuir entre los diferentes miembros de un Redis Cluster y además permite el acceso a miembros concretos, no sólo al hash completo) o incluso fuera de Redis.
- Usar un único Stream de gran tamaño vs varios más pequeños. Depende de qué caso de uso, puede tener más sentido una cosa u otra. Si quisiéramos registrar los eventos de acceso a la API de nuestra aplicación, podríamos utilizar un único Stream, que en aplicaciones de uso masivo sería una gran Stream, y tendría sentido así. Pero si queremos modelar algo como el Buzón de Correo de varios usuarios, tiene sentido que cada Buzón sea un Stream. Y como estos, hay más casos.
Despedida y Cierre
Hasta aquí llega este Post, en el que hemos intentado explicar en qué consiste un Redis Streams, una alternativa a Apache Kafka, consistente en una solución de mensajería para Streams de datos que llegan continuamente, son almacenados (ofrece persistencia), y procesados en tiempo real con garantía de entrega y de procesamiento, ideal para entornos de IoT, Big Data, o comunicación asíncrona entre micro-servicios, escalable y tolerante ante fallos.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.