
Redis es una base de datos NoSQL en memoria, sin esquema, single-thread, Open Source, e implementada en lenguaje C, que ofrece un alto rendimiento y resulta especialmente útil en casos de uso como el cacheo de datos (optimizando el uso de las bases de datos relacionales), almacén de sesiones, e incluso service broker. En este Post vamos a tratar las diferentes estructuras de datos de Redis: Strings, Hashes, Lists, Sets, y Sorted Sets
Comenzamos una nueva serie de Posts, en este caso sobre Redis (acrónimo de Remote dictionary server), una de las bases de datos NoSQL que más se usan hoy en día, principalmente para usos como Caché, también para el almacenamiento de Sesión y Aplicación en entornos Web, y otros muchos usos. Y como primer artículo, qué mejor que hacer una introducción a modo de preliminares y seguir con una explicación de las diferentes Estructuras de Datos de Redis, para comprender en qué consisten y posibles casos de uso de cada una.
Preliminares
Podemos ejecutar Redis de forma sencilla con Docker (docker run), para luego abrir una sesión de Bash sobre el contenedor Docker de Redis que hemos creado (docker exec), y poder ejecutar comandos como redis-cli (la interfaz de comandos de Redis, muy útil). Con esto, podremos trastear de forma sencilla. A continuacion se muestra un ejemplo, que nos servirá tanto en Ubuntu, como en Raspbian (Raspberry), etc.
docker run -d -p 6379:6379 --rm --name myredis redis:6.0
docker exec -it myredis /bin/bash
redis-cliredis-cli es la herramienta de línea de comandos para interaccionar con Redis, que nos permitirá ejecutar comandos Redis. Se instala por defecto al instalar un servidor de Redis, aunque también la podríamos compilar nosotros mismos, si nos aburrimos, su código está en GitHub.
- redis-cli se puede ejecutar en modo interactivo. Simplemente, ejecutamos
redis-clidesde nuestra shell, y entramos en un prompt donde interaccionar con redis. - redis-cli se puede ejecutar en modo imperativo. Por ejemplo, el comando
redis-cli get my-key
Podemos hacer muchas cosas más con redis-cli, como cargas masivas (o ejecuciones masivas de comandos Redis), analizar el espacio de claves buscando claves grandes, monitorizar los comandos ejecutados en Redis, o mostrar información estadística de forma continua cada segundo (ej: keys, mem, #clients, #connections, etc) para comprobar la salud de nuestro sistema, y muchas cosas más.
redis-cli --pipe < MULTIPLE_COMMANDS_MASSIVE_INSERT.txt
redis-cli --bigkeys > BIGKEYS_REPORT.log
redis-cli MONITOR > MONITOR_COMMANDS.log
redis-cli --statRedis utiliza el protocolo RESP (Redis Serialization Protocol) a través de TCP, lo que hace que sea posible ejecutar comandos Redis desde una simple conexión TCP a través de telnet o netcat (nc), como se ve en la siguiente pantalla, aunque evidentemente será mucho más sencillo si utilizamos herramientas como redis-cli o Redisinsight, o las librerías de programación correspondientes al lenguajes que utilicemos, en lugar de trabajar a tan bajo nivel.

Los clientes Redis, pensando en las librerías cliente de Redis utilizadas por los diferentes lenguajes de programación para poder conectarse a un servidor Redis, suelen ofrecer las siguientes funcionalidades para ayudar a optimizar el rendimiento:
- Connection Pooling. Crear y eliminar conexiones a Redis de forma continuada y repetida en el tiempo, genera una carga innecesaria en el servidor Redis que aumenta el consumo de CPU. Al habilitar Connection Pooling a través de nuestra librería cliente, se consigue crear un conjunto de conexiones persistentes a Redis, que se mantendrán abiertas y se reutilizarán por los diferentes threads o procesos, evitando crear y eliminar conexiones repetidas veces, y optimizando el rendimiento.
- Pipelining. Por defecto, para cada comando Redis se envía una petición a Redis, que la procesa y devuelve una respuesta. Este round trip requiere un tiempo (RTT – Round Trip Time), algo que habitualmente sucede en el tiempo de forma secuencial, es decir, si ejecutásemos 100 comandos el tiempo total sería 100*RTT. La técnica de Pipelining permite enviar varios comandos a la vez a Redis, que devolverá varias respuesta a la vez, todo en el mismo round trip, lo que ayuda a minimizar el tiempo total necesario para su procesamiento, al minimizar el número total de round trips para gestionar un mismo número de comandos. Además permite a Redis procesar nuevas peticiones incluso aunque el cliente aún no haya leído la respuesta de peticiones anteriores.
Otra forma habitual de mejorar el rendimiento en Redis es mediante la incorporación de una o varias Réplicas de lectura, de tal modo, que las escrituras vayan contra el Master, y las lecturas contras las Réplicas de sólo lectura, distribuyendo así la carga entre varios servidores, de forma sencilla.
Redis está formado por bases de datos lógicas (identificadas por un índice que comienza en cero) que actúan como espacios de nombre planos, de tal modo que en diferentes bases de datos pueden existir claves con el mismo nombre, sin llegar a existir un nivel jerárquico intermedio, como podrían ser las Colecciones.
La base de datos por defecto es la cero (db0), y aunque por defecto tendríamos disponible hasta la db15, un Cluster de Redis sólo permite trabajar con db0, por lo que en general es recomendable que nos acostumbremos a trabajar sólo con db0, en previsión de restricciones como esta (muchas aplicaciones y herramientas asumen trabajar con db0). Y para esto es muy importante definir bien qué nombres vamos a dar a nuestras claves, ya que en aplicaciones grandes con múltiples microservicios, podríamos acabar teniendo problemas de colisión, que podemos evitar fácilmente siguiendo una convención de nombres.
Otro detalle importante es que Redis en una base de datos Single-Thread, lo que evita condiciones de carrera y sobrecarga de CPU por context-switching asociado a múltiples hilos. Pero esto tiene varias implicaciones a tener en cuenta:
- Si durante la ejecución de un comando, se solicita a Redis la ejecución de otros dos, por lo que cada comando se ejecutará secuencialmente y de forma atómica (cada comando se ejecutará de forma completa e independiente, o en caso de fallo, no aplicarán ningún cambio a la base de datos para mantener su integridad), por lo tanto los otros dos estarán sometidos a esperas, fruto de dicha secuencialidad.
- No por poner muchos procesadores en el servidor de Redis, vamos a conseguir mejorar el rendimiento. En una aplicación orientada a micro-servicios será más eficiente tener un Redis para cada micro-servicio, que un único Redis para todos (mejor varios Redis para diferentes dominios o propósitos, que uno para todo).
Como cada comando Redis es atómico (se ejecuta de forma completa e independiente, o en caso de fallo, no aplicarán ningún cambio a la base de datos) para mantener la integridad, en algunos casos podemos necesitar el uso de Transacciones en Redis, para de esta forma poder ejecutar varios comandos de forma atómica, como si fuera uno solo, y que se ejecuten todos o en caso de fallo no se ejecute ninguno, para así poder garantizar la integridad de nuestros datos.
Sin embargo las Transacciones en Redis no son exactamente igual a como lo son en las bases de datos relacionales. No es posible crear Transacciones anidadas en Redis, y tampoco existe la posibilidad de ejecutar un Rollback (si una transacción incluye un comando con un error de sintaxis, la Transacción completa será descartada, en cualquier otro caso, será ejecutada). Esto permite a Redis que pueda ofrecer un máximo rendimiento y mínima latencia, y encaja perfectamente con su modelo Single-Thread.
Si lo deseamos, podemos descargar de forma gratuita (sólo requiere registro) la herramienta gráfica de RedisInsight, disponible para Windows, Linux y Mac, que te ayudará centralizar las conexiones a tus bases de datos, a explorar su contenido, ver estadísticas, acceder de forma rápida a una CLI de Redis, etc.
Introducción a las Claves (Keys) en Redis
Las claves (Keys) son la forma habitual de almacenar y recuperar datos en Redis, que serán almacenados en memoria RAM, en un espacio de claves plano, donde el desarrollador tiene libertad en cómo organizarlo (nomenclatura). Habitualmente se sigue la siguiente convención en los nombres de las claves en Redis: object-name:identifier:composed-object
Un ejemplo de nombre de una Clave, podría ser el siguiente, para una clave que representa los grupos del usuario 100001: user:100001:groups
Si bien, no es de obligado seguimiento, es recomendable seguir cierta nomenclatura o convención de nombres, sea esta u otra, y ser consistente en los nombres de todas las claves, especialmente si trabajamos en equipo con más personas, teniendo en cuenta que el nombre de una clave puede ser de hasta 512MB. Es fundamental, ya que es espacio de nombres en una base de datos Redis es plano, al no existir Colecciones o Tablas, y es necesario recurrir a una nomenclatura clara, para evitar colisiones.
Las Claves (Keys) pueden ser de un tipo u otro, que principalmente se refiere a la Estructura de Datos que utiliza, y suele condicionar qué comandos se usan para manipular la Clave. Las principales Estructuras de Datos son Strings, Hashes, Lists, Sets, y Sorted Sets.
Podemos utilizar los comandos SET y GET a través de redis-cli, para establecer el valor de una clave de tipo String así como obtener su valor, respectivamente. SET creará la clave si no existe, o bien, actualizará su valor si existía previamente. A continuación se muestra un ejemplo del uso de SET y GET, donde aprovechamos también para crear 20 claves de tipo String que usaremos en otros ejemplos.
set user:100001 willie
get user:100001
set user:100002 frank
set user:100003 mary
set user:100004 fred
set user:100005 simon
set user:100006 russel
set user:100007 bart
set user:100008 tom
set user:100009 sam
set user:100010 boris
set user:100011 tim
set user:100012 will
set user:100013 george
set user:100014 bruce
set user:100015 leo
set user:100016 john
set user:100017 brad
set user:100018 matt
set user:100019 rob
set user:100020 seanEs posible comprobar si existe una clave String utilizando el comando EXISTS, que devolverá 1 si la clave existe y 0 en caso contrario.
Sin embargo, si queremos crear un clave String sólo si no existe, no debemos utilizar un comando EXISTS seguido de un comando SET condicionado al resultado de EXISTS. En casos como este, es más eficiente utilizar un único comando SET con las opciones NX ó XX según lo que necesitemos:
- Opción NX del comando SET (non exist). El comando SET se ejecuta sólo si la clave no existía previamente.
- Opción XX del comando SET (exist). El comando SET se ejectua sólo si la clave existía previamente.
A continuación se muestra un ejemplo del uso de las opciones NX y XX del comando SET.
set user:100032 ted NX
set user:100032 rob NX
get user:100032
set user:100032 rob XX
get user:100032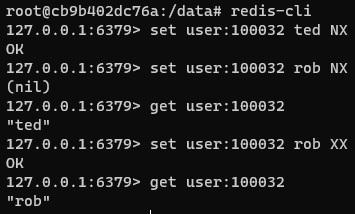
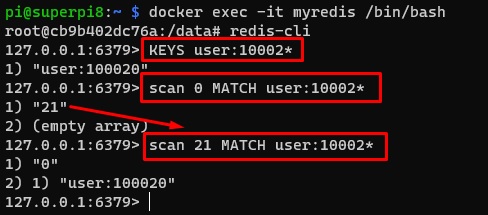
Podemos utilizar los comandos KEYS y SCAN a través de redis-cli, para obtener una lista de los nombres de claves en la base de datos, ya sea de todos o bien sólo de aquellos que cumplan cierto patrón. Es muy importante comprender las diferencias entre ambos:
- KEYS. Siempre bloquea la base de datos hasta que acaba, por lo que no está recomendado su uso en Producción (especialmente con bases de datos grandes). Sin embargo, debido a su facilidad de uso, es habitual utilizarlo en local, o incluso en entornos de desarrollo y de pruebas, pero con precaución.
- SCAN. Itera la base de datos en bloques (batches) mediante un cursor, lo que evita bloquear completamente la base de datos durante un tiempo prolongado, siendo una alternativa al comando KEYS, para su uso de forma segura en Producción, aunque es un poco más complicado y suele requerir la ejecución de varios comandos SCAN (varios batches) para obtener el resultado deseado (en lugar de un único comando KEYS). Cada llamada a SCAN requiere como parámetro el valor de un cursor, que en la primera llamda será 0. SCAN devolverá un valor de cursor 0 cuando ya no queden más claves sobre las que iterar, y un valor distinto cuando aún queden claves, para utilizar en la siguiente llamada.
A continuación se muestra un ejemplo de KEYS y SCAN, donde se puede observar como para obtener el mismo resultado con SCAN es necesario realizar varias llamadas (batches), y como en las sucesivas llamadas a SCAN usamos el valor de cursor devuelto en la llamada anterior.
Podemos utilizar los comandos DEL y UNLINK a través de redis-cli, para eliminar una clave.
- DEL. Eliminará la clave y la memoria asociada con la misma, resultando en una operación que genera un bloqueo.
- UNLINK. Elimina la asociación entre la clave y su valor (el espacio de memoria que usaba). La memoria será liberada mediante un proceso asíncrono, lo que permite que no se genera un bloqueo.
Expiración de Claves (Keys)
Las Claves (Keys) se almacenan en memoria RAM, por lo que suele ser una buena práctica establecer una expiración a las mismas (en ms, seg, o un timestamp), tanto en la creación de la clave (ej: con el comando SET) como posteriormente a su creación (ej: con los comandos EXPIRE, PEXPIRE, EXPIREAT, ó PEXPIREAT). También podemos comprobar el valor de la expiración de una Clave con los comandos TTL y PTTL, incluso eliminar la expiración de una Clave con el comando PERSIST. Esto nos ayudará a evitar un consumo excesivo de memoria que pueda ser contraproducente.
Tipo de dato String
El tipo de dato más habitual en Redis es el String, ya que permite almacenar en su interior cualquier tipo de información, incluyendo valores numéricos, binarios, valores separados por comas (o por cualquier otro separador), JSON serializados, e incluso objetos grandes como imágenes, sonido, documentos, o video, cualquier cosa. Ya hemos visto en el apartado anterior, algunos ejemplos y comandos con claves de tipo String.
Podemos almacenar en un String, un objeto que ha sido previamente serializado (ya sea en formato binario o texto), aunque en este caso hay que tener en cuenta, que siempre tendremos que acceder al objeto completo (lo que implica transferirlo por la red, así como serializarlo y/o deserializarlo). Si necesitamos poder acceder o modificar sólo una propiedad, nos puede interesar almacenarlo como un Hash, en lugar de como un String, para así poder acceder a sus propiedades de forma independiente.
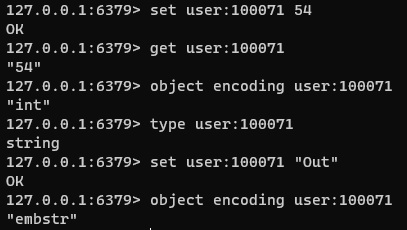
Aunque en todos los casos estamos trabajando con un String en Redis, el valor de un String se almacena con un encoding determinado, que nos permite en ciertos casos conocer la naturaleza de nuestro dato (ej: un INT), y que podemos consultar con el comando OBJECT. De este modo, es como por ejemplo Redis sabe si puede ejecutar un comando INCR sobre una clave, aunque también hay que tener en cuenta, que en cualquier momento podríamos almacenar un dato de otra naturaleza, y no habría inconveniente (no hay un esquema que fuerce que tipo de valor podemos almacenar, como ocurriría en una base de datos relacional). A continuación lo podemos ver con un ejemplo.
set user:100071 54
get user:100071
object encoding user:100071
type user:100071
set user:100071 "Out"
object encoding user:100071La ejecución de los anteriores comandos en redis-cli produciría la siguiente salida, que representa con claridad lo que intentamos explicar.
Su uso más habitual es como caché (aquí resulta especialmente útil la expiración de claves): respuestas de API, respuestas HTML, almacenamiento de sesión, etc., pero también se puede utilizar como un contador o secuencia, gracias a comandos como INCR, INCRBY, DECR y DECRBY, o el comando INCRBYFLOAT.
A continuación se muestra un ejemplo, en el que se cachea en Redis por 2 horas (7200 seg), información de un usuario como un JSON en un String, y seguidamento comprobamos con el comando TTL cuandos segundos quedan para que expire.
set user:100074 '{"name":"Tom","region":"south-europe","currency":"EUR","groups":["editor","admin"]}' EX 7200
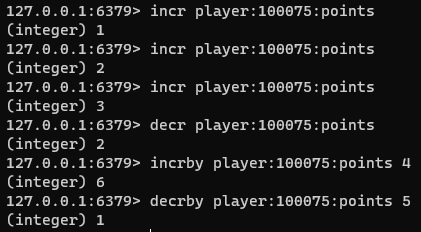
ttl user:100074A continuación se muestra un ejemplo utilizando los comandos INCR, INCRBY, DECR, y DECRBY. Hay que tener en cuenta, que la variable del ejemplo no existía previamente, por lo que el primer comando la inicializa a 1.
incr player:100075:points
incr player:100075:points
incr player:100075:points
decr player:100075:points
incrby player:100075:points 4
decrby player:100075:points 5La ejecución de cada comando, devuelve el valor actualizado de la variable, como se ve en la siguiente pantalla capturada.
Redis permite almacenar datos binarios en un String, un array de bits que puede ser almacenado y manipulado en Redis, permitiéndose operaciones a nivel de Bit (ej: comandos SETBIT, GETBIT, BITPOS, y BITCOUNT – que cuenta sólo los bits a 1). Además, el comando BITOP permite operaciones de bit como AND, OR ó XOR.
El comando BITFIELD permite obtener, modificar, e incrementar un valor dentro de un campo de bits. A continuación se muestra un ejemplo, en el que escribimos el valor decimal 65 como un entero sin signo de 8 bits (u8) al comienzo (el offset es 0), que coincide con el carácter ASCII de la «A», y que posteriormente lo incrementamos en 1 convirtiéndolo en el valor 66 que coincide con la «B».
bitfield binary-map set u8 0 65
bitfield binary-map get u8 0
get binary-map
bitfield binary-map incrby u8 0 1
get binary-map
type binary-map
object encoding binary-mapA continuación se muestra el resultado de ejecución de los anteriores comandos en redis-cli.

Hashes
El tipo de dato Hash permite almacenar una colección no ordenada de parejas campo-valor (Strings), es un tipo de dato mutable y sin esquema (schemaless) que podemos modificar (añadir, modificar, o eliminar sus parejas de campo-valor, con libertad y en cualquier momento). Es un tipo de dato plano (no permite anidar arrays, por ejemplo). Podemos verlo como algo parecido a un JSON, un Diccionario en Python (pero plano, claro), un array de PHP, un fila de una tabla de una base datos relacional, o simplemente modelar una entidad o un objeto ligero.
Si necesitamos trabajar con JSON, podemos utilizar el módulo RedisJSON en lugar de Hashes, que nos permitirá anidar valores, y proporciona comandos propios para trabajar con JSON en Redis.
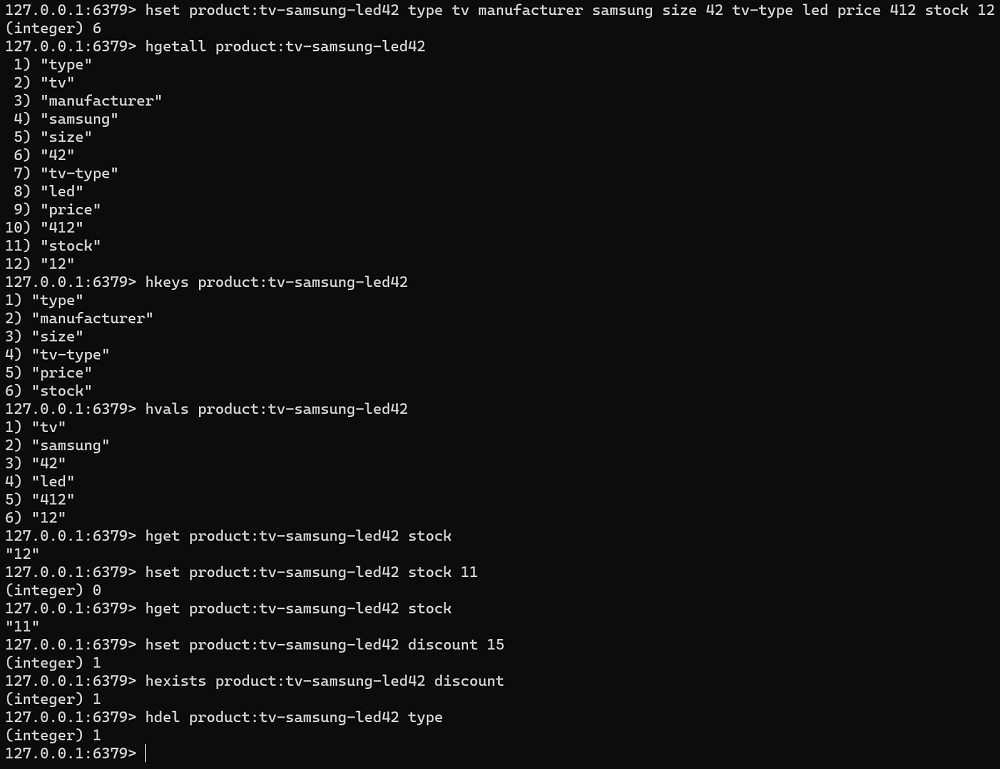
Para trabajar con Hashes utilizaremos principalmente los comandos HSET, HGET, HDEL, HGETALL y HSCAN (HSCAN es más recomendable que HGETALL, de forma similar a como ocurre con KEYS y SCAN), aunque hay otros comandos que nos podrán ser de utilidad como HKEYS, HVALS, HEXISTS, HSETNX, HMGET, INCRBY, HINCRBYFLOAT, etc. Podemos obtener o modificar el valor de un campo concreto (ej: stock), añadir nuevos campos (ej: discount), o eliminar un campo (ej: type). A continuación se muestra un ejemplo de comandos que podríamos lanzar desde redis-cli:
hset product:tv-samsung-led42 type tv manufacturer samsung size 42 tv-type led price 412 stock 12
hgetall product:tv-samsung-led42
hkeys product:tv-samsung-led42
hvals product:tv-samsung-led42
hget product:tv-samsung-led42 stock
hset product:tv-samsung-led42 stock 11
hget product:tv-samsung-led42 stock
hset product:tv-samsung-led42 discount 15
hexists product:tv-samsung-led42 discount
hdel product:tv-samsung-led42 typeA continuación se muestra el resultado de ejecución de los anteriores comandos en redis-cli.
En el caso de querer almacenar objetos complejos (objetos jerárquicos con propiedades distribuidas en varios niveles de profundidad), un Hash no es suficiente, y es necesario recurrir a algún mecanismo adicional. Las principales alternativas son:
- Utilizar un único Hash, aplanando la jerarquía. Es quizás la opción más simple, aunque la gestión de la relaciones jerárquicas puede volverse complicada, y podemos acabar con muchos campos convirtiéndose en algo tedioso. Es importante jugar con la nomenclatura de los campos, para simular dicha jerarquía. Por ejemplo, podemos tener los siguientes campos dentro del mismo Hash:
- seats:general:quantity
- seats:general:price
- seats:vip:quantity
- seats:vip:price
- Utilizar múltiples Hashes, de tal modo que cada objeto (plano) es almacenado en su propio Hash. Se trata de hacer una especie de ejercicio de normalización, como si se tratase de un diagrama UML, rompiendo a cada nivel de la jerarquía en un nuevo Hash. Por ejemplo, para un objeto, podríamos utilizar los siguientes Hashes:
- event:1001
- event:1001:seats:general
- event:1001:seats:vip
- Utilizar múltiples Hashes y Sets. Cada objeto (plano) es almacenado en un Hash, como en el caso anterior, pero además, las relaciones entre objetos se almacenan en Sets adicionales, resultando en una solución más compleja y que requiere memoria adicional. Siguiendo con el ejemplo del caso anterior, sería necesario el siguiente Set, al cual deberíamos añadir las referencias a los objetos hijos (event:1001:seats:general y event:1001:seats:vip).
- event:1001:seats
Un caso de uso podrían ser una base de datos de productos, donde cada producto se almacene como un Hash con clave product:product-name, y las parejas de campo y valor sean las propiedades del producto.
Otro caso de uso podría ser un sistema de control de peticiones a APIs (rate limit), donde cada API se almacene como un Hash con clave rate-limit:invoince-api, y las parejas de campo y valor sean los endpoints de la API con un valor entero, que estableceremos (HSET) cada cierto tiempo con un valor, y que decrementaremos (HINCRBY) en cada llamada.
Lists
El tipo de dato List permite almacenar una colección ordenada de valores (Strings) de hasta 4 billones, que podemos utilizar para almacenar simplemente una colección de valores, pero también para implementar pilas o colas. Redis implementa las Listas como una Lista de elementos doblemente enlazadados (no como un Array), donde cada elemento tiene un puntero al elemento anterior y otro al posterior. El orden se garantiza habitualmente en base a la inserción y borrado de elementos (por uno u otro extremo de la Lista, no es habitual insertar elementos en su interior), siendo posible la existencia de elementos duplicados. Podemos verlo como algo parecido a un ArrayList de Java, un array de Java, o una Lista de Python.
- Podemos añadir elementos (Push) a una Lista con los comandos LPUSH ó RPUSH, que devuelven el número de elementos o longitud de la Lista.
- Podemos sacar elementos (Pop) de una Lista con los comandos LPOP ó RPOP, que devuelven el elemento que se ha sacado de la Lista de forma inmediata, o nil en caso de estar vacía.
- Podemos sacar elementos (Pop) de una Lista con los comandos BLPOP ó BRPOP, que devuelven el elemento que se ha sacado de la Lista, o en caso de estar vacía se queda esperando un tiempo determinado (a diferencia de LPOP o RPOP).
- Podemos implementar una cola, añadiendo elementos por la derecha (RPUSH) y sacándolos por la izquierda (LPOP), o bien al contrario (LPUSH y RPOP).
- Podemos implementar un pila, añadiendo elementos por la derecha (RPUSH) y sacándolos igualmente por la derecha (RPOP), o bien al contrario (LPUSH y LPOP).
- Podemos obtener el elemento existente en una posición determinada con el comando LINDEX.
- Podemos insertar un nuevo elemento, en el interior de la Lista (que no sea de los extremos, sea antes o después de otro existente), con el comando LINSERT.
- Podemos actualizar el valor de un elemento existente con el comando LSET.
- Podemos eliminar un elemento existente, del interior de la Lista (que no sea de los extremos), con el comando LREM.
- Podemos obtener el número de elementos de una Lista con el comando LLEN.
- Podemos recortar la Lista especificando un rango de índices, mediante el comando LTRIM (ojo, no existe ningún comando RTRIM), lo que permitiría recortar la Lista para reducirla, por ejemplo, a un TOP3. Un valor de índice negativo, referencia los elementos comenzando desde el final de la lista (desde la derecha), com
- Podemos obtener un conjunto de elementos de una Lista mediante el comando LRANGE, especificando el índice del primer y último elemento que deseamos mostrar, lo que nos permitirá mostrar los primeros 5 elementos de una lista (ej: LRANGE waitlist:acdc-tour-madrid 0 4), e ir paginando sobre el resto (ej: LRANGE waitlist:acdc-tour-madrid 5 9), etc. Si queremos seleccionar todos los elementos, especificaremos como índices 0 y -1 (ej: LRANGE waitlist:acdc-tour-madrid 0 -1), por lo que deberemos ser prudentes al trabajar con grandes Listas, para evitar impactar en el rendimiento.
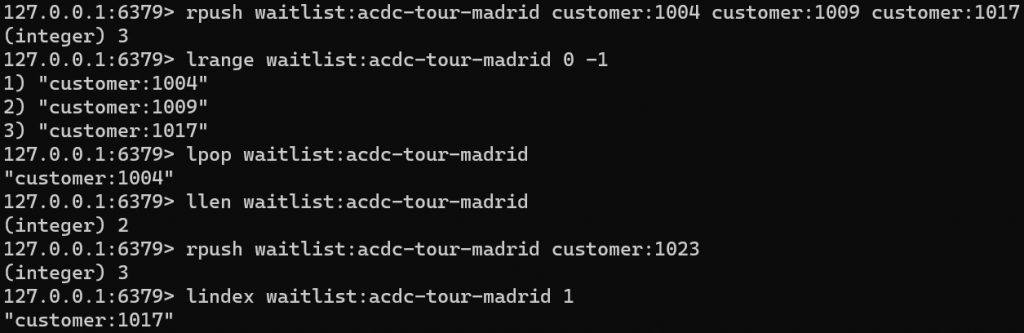
A continuación se muestra un ejemplo de comandos que podríamos lanzar desde redis-cli.
rpush waitlist:acdc-tour-madrid customer:1004 customer:1009 customer:1017
lrange waitlist:acdc-tour-madrid 0 -1
lpop waitlist:acdc-tour-madrid
llen waitlist:acdc-tour-madrid
rpush waitlist:acdc-tour-madrid customer:1023
lindex waitlist:acdc-tour-madrid 1A continuación se muestra el resultado de ejecución de los anteriores comandos en redis-cli.
Es posible implementar colecciones limitadas, con el patrón RPUSH + LTRIM, de tal modo que si queremos tener una Lista limitada a 20 elementos, después de cada inserción (RPUSH), ejecutaríamos LTRIM para recortar el número de elementos.
Un caso de uso podría ser una Playlist de música o de videos, que a fin de cuentas, es un conjunto de elementos implementado en forma de una cola, para su ejecución o procesamiento en orden.
Otros casos de uso, podrían ser una lista de espera (waitlist), una clasificación (ej: resultado de una competición), o un historial (ej: podríamos almacenar el historial de navegación de nuestros usuarios con una Lista para cada usuario, con clave history:10001 donde el valor numérico es el código del usuario… o un historial de actividad, como nuestra actividad en una red social como Facebook).
También podríamos utilizar una Lista para implementar un patrón Productor-Consumidor, donde dos procesos se puedan comunicar permitiendo que un consumidor reciba los mensajes o eventos en el mismo orden en que se han producido, para su procesamiento.
Sets
El tipo de dato Set permite almacenar una colección no ordenada de valores únicos (Strings), es decir, que no contiene duplicados, y que además permite operaciones matemáticas de conjuntos como intersección, diferencia, y unión.
Algunos comandos útiles para trabajar con Sets, serían los siguientes:
- Podemos añadir elementos con el comando SADD.
- Podemos sacar un elemento específico con el comando SREM.
- Podemos sacar un elemento aleatorio con el comando SPOP.
- Podemos conocer el número de elementos con el comando SCARD.
- Podemos mostrar los elementos con el comando SMEMBERS o también con el comando SSCAN (más eficiente).
- Podemos comprobar si contiene un elemento con el comando SISMEMBER.
- Podemos obtener la intersección entre dos conjuntos con el comando SINTER. También podemos usar el comando SDIFF para obtener la diferencia entre dos conjuntos, y el comando SUNION para la unión de ambos.
A continuación se muestra un ejemplo de comandos que podríamos lanzar desde redis-cli.
sadd devices:online 10.0.0.1
sadd devices:online 10.0.0.2 10.0.0.3 192.168.0.1
scard devices:online
smembers devices:online
sscan devices:online 0 match *
sismember devices:online 192.168.0.1
sadd devices:spain 192.168.0.1
sinter devices:online devices:spainA continuación se muestra el resultado de ejecución de los anteriores comandos en redis-cli.

Un caso de uso podría ser implementar un sistema de control de presencia de dispositivos, mediante un Set con clave devices:online que almacene los diferentes dispositivos que están online, lo cuales actualizarían su IP en el conjunto cada minuto. Una versión mejora podría trabajar con dos Sets (timed-scoped keys), uno para la franja temporal actual (ej: devices:online:1000), y otra para la siguiente franja temporal (ej: devices:online:1005), de tal modo, que cada vez que un dispositivo actualiza su estado lo hace en ambos Sets, y cada 5 min (o el periodo que se decida), se rotan de tal modo que se elimina el Set de la franja temporal actual sustituyéndola por el de la siguiente franja temporal, y se crea un nuevo Set vacío para la siguiente franja temporal (realmente, esto lo podemos conseguir con la Expiración de claves, y simplemente acceder en cada momento a los Sets correctos, en función de la hora del sistema). Así conseguimos reflejar los dispositivos que han dejado de actualizar su estado, y que por lo tanto, no están online.
La nube de Tags de un Blog también se podría implementar con un conjunto (Set), o podríamos implementar un control de visitantes únicos a una Web, mediante un Set para cada página, con clave similar a visits:aboutus.html donde añadir las IPs de los visitantes.
Sorted Sets
El tipo de dato Sorted Set permite almacenar una colección ordenada de valores únicos (Strings) – no permite duplicados – con un valor de puntación (floating point score) asociado a cada miembro que es utilizado como criterio de ordenación, del más bajo al más alto, aunque los miembros pueden ser accedidos en orden ascendente o descendente. La puntación (score) de cada miembro, se puede incrementar o decrementar, lo que puede cambiar al orden de los miembros. Además permite operaciones matemáticas de conjuntos como intersección y unión (la diferencia no era posible, hasta Redis 6.2, que se introdujo ZDIFF).
Algunos comandos útiles para trabajar con Sorted Sets, serían los siguientes:
- Podemos añadir elementos (o actualizar su puntación/score, si ya existían) con el comando ZADD. Incluye las opciones NX (Nox Exists) y XX (Exists), como ocurría con el comando SET.
- Podemos conocer el número de elementos con el comando ZCARD.
- Podemos incrementar o decrementar la puntación (score) de un miembro con el comando ZINCRBY.
- Podemos eliminar un miembro, en función de su valor (independientemente de su puntación/score), con el comando ZREM. También es posible utilizar otros comandos similares, como ZREMRANGEBYLEX, ZREMRANGEBYRANK (equivalente a LTRIM en las Listas, sería permitiría eliminar todos los elementos excepto el TOP3), y ZREMRANGEBYSCORE.
- Podemos recorrer los miembros en función de su posición (su índice), de principio a fin (de menor a mayor), o en orden contrario, con los comandos ZRANGE y ZREVRANGE. Esto es útil para conseguir un TOP3, y otras consultas parecidas.
- Podemos recorrer los miembros en función de su puntuación (score), de principio a fin (de menor a mayor), o en orden contrario, con los comandos ZRANGEBYSCORE y ZREVRANGEBYSCORE.
- Podemos obtener la posición (ranking) de un miembro con el comando ZRANK. Hay que tener en cuenta que el primer miembro (el de puntación más baja) será el cero, el siguiente el uno, y así sucesivamente, pudiendo utilizar el comando ZREVRANK para obtener la posición en orden inverso (primero el miembro con la puntuación más alta).
- Podemos obtener la puntación (score) de un miembro con el comando ZSCORE.
- Podemos obtener cuantos miembros tienen una puntación (score) dentro de un rango entre dos puntuaciones (ambas inclusives), con el comando ZCOUNT.
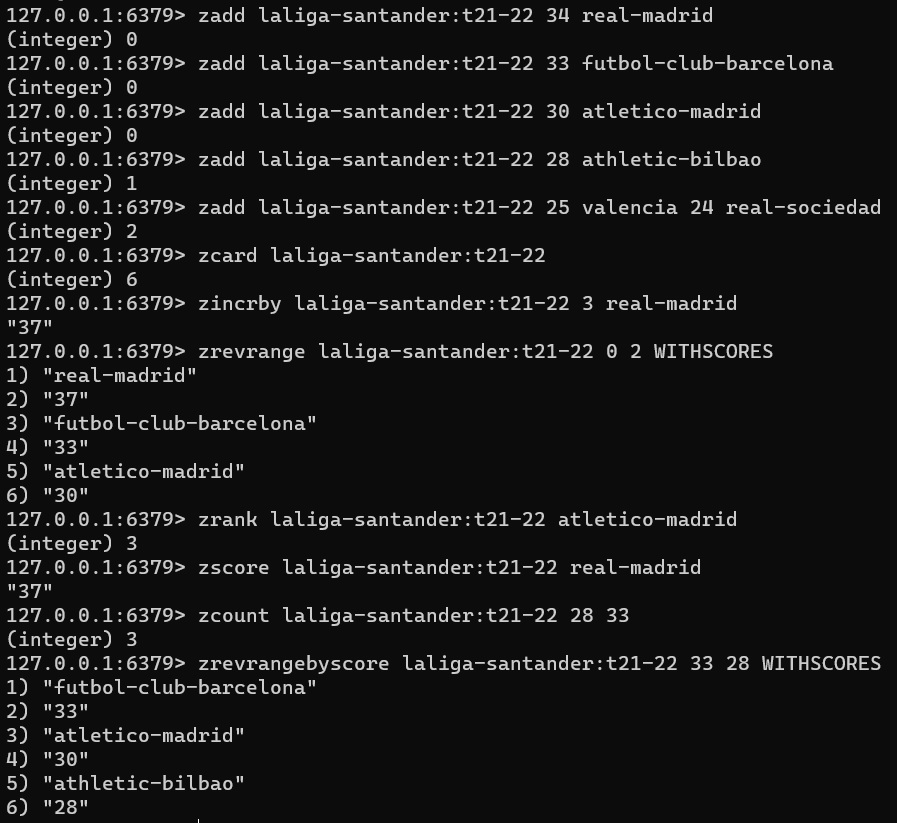
zadd laliga-santander:t21-22 34 real-madrid
zadd laliga-santander:t21-22 33 futbol-club-barcelona
zadd laliga-santander:t21-22 30 atletico-madrid
zadd laliga-santander:t21-22 28 athletic-bilbao
zadd laliga-santander:t21-22 25 valencia 24 real-sociedad
zcard laliga-santander:t21-22
zincrby laliga-santander:t21-22 3 real-madrid
zrevrange laliga-santander:t21-22 0 2 WITHSCORES
zrank laliga-santander:t21-22 atletico-madrid
zscore laliga-santander:t21-22 real-madrid
zcount laliga-santander:t21-22 28 33
zrevrangebyscore laliga-santander:t21-22 33 28 WITHSCORESA continuación se muestra el resultado de ejecución de los anteriores comandos en redis-cli.
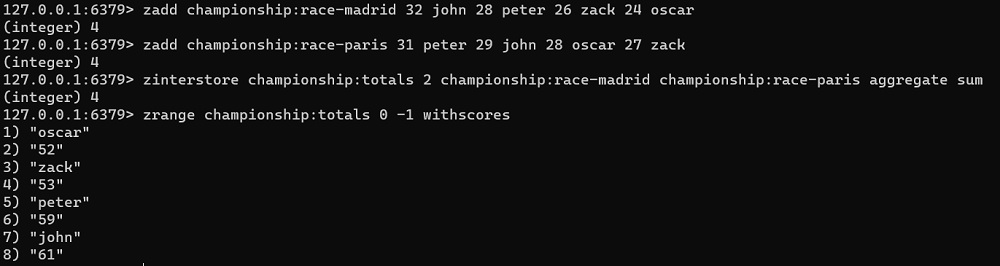
Al trabajar con operaciones de conjunto tenemos que tener en cuenta como tratar la puntuación (score). En el siguiente ejemplo, creamos un nuevo Sorted Set mediante una operación de intersección, aplicando la operación SUM a las puntaciones de los elementos existentes en los conjuntos origen, para calcular su valor en el conjunto final. Es decir, si oscar tiene 24 puntos en la carrera de Madrid y 28 en la de Paris, acabará con 52 puntos.
zadd championship:race-madrid 32 john 28 peter 26 zack 24 oscar
zadd championship:race-paris 31 peter 29 john 28 oscar 27 zack
zinterstore championship:totals 2 championship:race-madrid championship:race-paris aggregate sum
zrange championship:totals 0 -1 withscoresA continuación se muestra el resultado de ejecución de los anteriores comandos en redis-cli.
Es posible implementar colecciones limitadas, con el patrón ZADD + ZREVRANGEBYRANK, de tal modo que si queremos tener un Sorted Set limitado a 20 elementos, después de cada inserción (ZADD), ejecutaríamos ZREVRANGEBYRANK para recortar el número de elementos.
Un caso de uso típico sería una tabla de clasificación (leaderboard o top score) en tiempo real, que almacene un conjunto de participantes o jugadores, con su puntación asociada que puede cambiar a lo largo del tiempo, mateniéndose siempre ordenados, y permitiendo obtener de forma fácil datos como el TOP3 de la clasificación, la posición o ranking de cualquier miembro, o la posición de cualquier miembro. Aquí podría ser interesante una colección limitada, por ejemplo a 20 ó 100 elementos, apoyándonos en ZREVRANGEBYRANK.
Al igual que con las Listas, es posible implementar Colas o Pilas. Pero en este caso, además podríamos implementar Colas o Pilas Priorizadas, aprovechando la capacidad de ordenación en base a la puntuación (score), apoyándonos en comandos como ZRANGE sorted-set 0 0 y ZREM sorted-set item1.
Despedida y Cierre
Hasta aquí llega este Post, en el que hemos intentado realizar una introducción a Redias y a las estructuras de datos que soporta Redis (Strings, Hashes, Lists, Sets, y Sorted Sets), así como cierta orientación en los posibles casos de uso, y comandos de ejemplo, sin entrar en otros tipos de datos o estructuras más complejas, como sería el mecanismo de Publicación y Suscripción de Redis, o los índices geoespaciales.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.