
Una de las principales ventajas de OpenStack, es que se trata de una solución altamente escalable, pudiendo llegar a tener cientos o miles de servidores. En este Post vamos a hacer una pequeña introducción a la escalabilidad en OpenStack, así como ver el proceso para añadir un Compute Node a nuestra instalación de laboratorio (all-in-one) sobre CentOS 7 con Packstack.
Continuando con la serie de Posts sobre OpenStack, después de que tratáramos hace unos días cómo instalar OpenStack en CentOS 7 con PackStack así como un breve introducción a OpenStack, viéramos una introducción al Dashboard y CLI de OpenStack, y conociéramos el Servicio de Identidad (Keystone), el Servicio de Imágenes (Glance), el Servicio de Red (Neutron), el Servicio de Compute (Nova), y los Servicios de Almacenamiento Cinder (Block Storage) y Swift (Object Storage), ahora llega el turno de que podamos ver cómo hacer crecer nuestra instalación de OpenStack añadiendo más servidores, en particulas, cómo añadir un Compute node. Comenzamos.
Hasta ahora, hemos estado trabajando en un entorno de laboratorio instalado en modo all-in-one, es decir, una única máquina virtual donde corren todos los servicios de OpenStack que utilizamos. Visto así, en cierto modo es una castaña, porque se nos va gran parte de los recursos de nuestra máquina sólo para que arranque OpenStack. Pero en la realidad, esto no es así, ya que lo habitual es tener cientos o miles de servidores (escalable horizontalmente, es decir, pudiendo añadir más capacidad en cualquier momento), y en ese caso, los recursos dedicados a ejecutar OpenStack se distribuyen y diluyen entre todas estas máquinas, resultando despreciable.
La principal pregunta al diseñar una solución de OpenStack con cientos o miles de máquinas, es qué servicios deben ejecutarse en qué máquinas, y cómo escalar horizontalmente cada servicio. Hay muchas respuestas válidas, especialmente si bajamos a detalle y en función de cómo queramos diseñar nuestra solución OpenStack, qué componentes o proyectos necesitamos, qué hardware, y con qué propósito. Además, cada componente o proyecto de OpenStack tiene consideraciones específicas para escalarlo horizontalmente, aunque en la mayoria de los casos necesitaremos utilizar alguna solución de Load Balancing, para el acceso a las API REST y otros Endpoint HTTP, igual que tendremos que buscar soluciones de Clustering (ej: Galera Cluster) y alta disponibilidad para las bases de datos (ej: MySQL) y los servicios de colas (ej: RabbitMQ).
En nuestro caso, que partimos de una única máquina (all-in-one), la forma más razonable de crecer, sería simplemente añadir máquinas para utilizarlas como Compute Nodes, es decir, tendríamos un Controller Node (con todos los servicios excepto Compute), y varios Compute Nodes.
El siguiente paso, sería tener al menos dos Controller Nodes, varios Compute Nodes, y varios Network Nodes.
Finalmente acabaríamos con un propuesta similar a la siguiente, en la que podemos encontrar:
- Varios Controller Nodes, en los que correrían Keystone, Glance, Horizon, y los servicios core del resto de proyectos o componentes de OpenStack.
- Varios Network Nodes, que ejecutarían los servicios de Neutron, excepto el neutron-server que correría en los Controller Nodes.
- Varios Compute Nodes, que además del Hypervisor que deseemos utilizar (ej: KVM) ejecutaría los servicios de Nova y el agente de Neutron.
- Varios Block Storage Nodes, que ejecutarían los servicios de Cinder.
- Varios Object Storage Nodes, que ejecutarían los servicios de Swift.
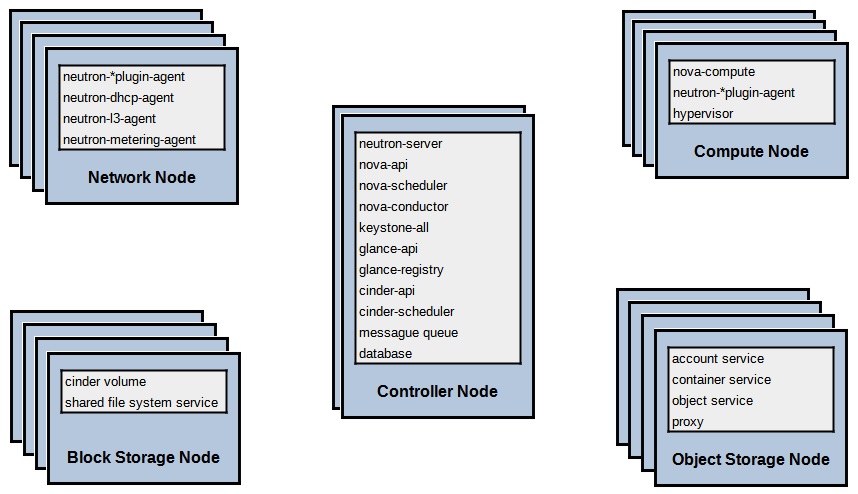
Un detalle importante, es elegir cómo queremos gestionar el almacenamiento de las Instancias en Nova. Hay varias opciones, que tienen ventajas e inconvenientes.
- Almacenamiento compartido, fuera de los Compute Nodes. En caso de fallo de un Compute Node, la recuperación es muy sencilla.
- Almacenamiento compartido en los Compute Nodes (sistema de ficheros distribuido).
- Almacenamiento local en los Compute Nodes.
Añadiendo un Compute Node
Vamos a ver cómo añadir un Compute Node a nuestra instalación all-in-one, de tal modo que tendremos un Controller Node que correrá todos los roles (incluyendo el de Compute), y un Compute Node adicional (dedicado sólo a Compute), por lo que pasaremos a tener dos Compute Nodes. Para ello:
- Crearemos una nueva máquina virtual con CentOS 7 y Packstack, con al menos 4GB de RAM e IP 192.168.10.174, que será el Compute Node, exactamente igual que ya hicimos en la instalación de OpenStack all-in-one original, mismas versiones de CentOS, Packstack, etc. La llamaremos openstack02.
- Añadiremos una segunda NIC a ambas máquinas, Controller Node y Compute Node (openstack01 y openstack02, respectivamente), para lo túneles de tráfico interno, con direccionamiento 10.10.10.0/24, y dirección IP fija. Será la interfaz eth1.
Para poder añadir un nuevo servidor a OpenStack, necesitaremos preparar un fichero de respuestas de Packstack. Partiremos del fichero de respuestas que generó automáticamente Packstack durante la instalación original (all-in-one). Nos conectaremos por SSH al Controller Node, haremos una copia, y lo modificaremos.
cp packstack-answers-20221101-193555.txt packstack-answers-compute-node.txt
vi packstack-answers-compute-node.txtA continuación podemos ver el comienzo del fichero de respuestas original, sobre el que deberemos realizar algunas modificaciones.
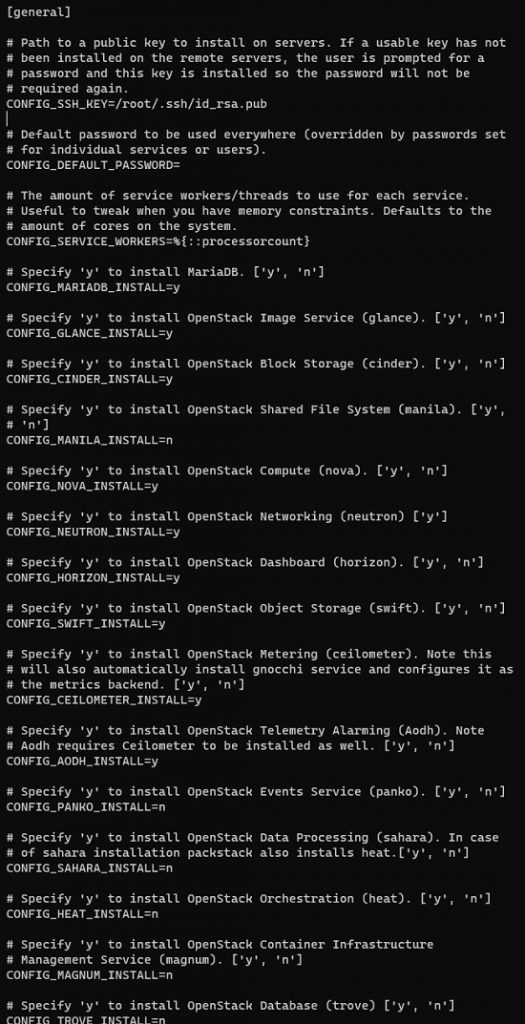
Las modificaciones que realizaremos, serán las siguientes:
- Especificaremos que los túneles de tráfico interno, se deberán crear desde la segunda NIC que acabamos de configurar. Esto lo haremos con los parámetros CONFIG_NEUTRON_OVS_TUNNEL_IF=eth1 y CONFIG_NEUTRON_OVS_TUNNEL_SUBNETS=10.10.10.0/24
- Especificaremos queremos tener dos Compute Nodes (el original y el nuevo servidor que queremos añadir, especificando sus direcciones IP (realmente se trata de añadir la IP del nuevo servidor), con el parámetro CONFIG_COMPUTE_HOST=192.168.10.175,192.168.10.174
- Dado que el actual servidor ya está configurado, especificaremos que sólo queremos configurar el nuevo servidor (el nuevo Compute Node). Para ellos utilizaremos el parámetro EXCLUDE_SERVERS=192.168.10.175 especificando la IP del Controller Node que ya tenemos configurado, para que se excluya
Realizado esto, podremos iniciar la instalación con Packstack, utilizando el fichero de respuestas que acabamos de personalizar.
packstack --answer-file=packstack-answers-compute-node.txtLa instalación será mucho más ligera que la original que hicimos, ya que en esta ocasión ya tenemos muchos servicios configurados, y tan sólo queremos añadir el de Compute a un nuevo servidor, y nada más.
En caso de errores, los podemos resolver de forma similar a como hicimos en la instalación original. Recordemos que encontraremos muchos Logs de utilidad bajo /var/log.
Una vez finalizada con éxito la instalación del nuevo Compute Node, podemos comprobarlo desde OpenStack CLI con el siguiente comando:
source keystonerc_admin
openstack hypervisor listDespedida y Cierre
Hasta aquí llega este Post de OpenStack, donde hemos podido tratar la escalabilidad horizontal en OpenStack, y ver el proceso a seguir para añadir un Compute Node, a nuestro entorno de laboratorio con CentOS 7 y una instalación all-in-one con Packstack.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.