
¿Qué es RabbitMQ? RabbitMQ es uno de los más populares servicios de colas de mensajes o message-broker, disponible desde el año 2007, Open Source y escrito en Erlang, que implementa el protocolo AMQP (Advanced Message Queuing Protocol) para la comunicación asíncrona mediante mensajes con garantía de entrega, y permite ser extendido mediante el uso Plugins para implementar funcionalidad adicional como los protocolos STOMP (Streaming Text Oriented Messaging Protocol) y MQTT (Message Queuing Telemetry Transport). RabbitMQ es una pieza fundamental para el desarrollo de soluciones asíncronas y/o desacopladas mediante el uso de cola de mensajes. ¿Quieres conocerlo mejor?
Comenzamos una serie de Posts sobre RabbitMQ, a través de los cuales intentaré contar algunos aspectos de este producto.
Existen muchas soluciones similares a RabbitMQ, tanto en modalidad de servicios Cloud, como productos de pago u Open Source, pero también existen muchas pequeñas diferencias entre todos ellos (dificil hacer una comparativa entre todos). Algunos ejemplos serían los siguientes: IBM MQ, Kafka, Apache ActiveMQ, Amazon MQ/Kinesis, Azure Event Bus, Google Cloud Pub/Sub, Tibco EMS/Messaging/Rendezvous, etc. Incluso como ya vimos hace unas semanas, también podríamos considerar como alternativas el mecanismo de publicación y suscripción de mensajes con Redis, así como Redis Streams (inspirado en Apache Kafka).
Para más info, puedes visitar la Web de RabbitMQ así como el GitHub de RabbitMQ.
Introducción a AMQP (Advanced Message Queuing Protocol)
El protocolo AMQP es un estándar abierto, por lo que en teoría deberíamos poder sustituir RabbitMQ de forma transparente por cualquier otro producto que también implemente AMQP, o al revés.
AMQP está diseñado para la comunicación asíncrona mediante el almacenamiento de mensajes en una cola, estandarizando el comportamiento del Publicador y el Consumidor, que no necesitan trabajar al mismo ritmo, siendo procesos desacoplados e independientes (pueden estar escritos en lenguajes de programación distintos y ejecutarse sobre plataformas diferentes, utilizando el SDK correspondiente).
Uno de los elementos principales de AMQP es el mensaje, que está formado por las siguientes tres estructuras, pudiendo alcanzar un tamaño de hasta 2GB, aunque la recomendación es el uso de mensajes pequeños:
- Header (parejas de clave/valor). Definidos por la especificación AMQP.
- Properties (parejas de clave/valor). Específicos de cada aplicación.
- Body (payload). Secuencia de bytes.
Introducción a las Colas de Mensajes (Messages queues)
Una cola de mensajes es una colección ordenada de mensajes que permite tanto la adición de mensajes nuevos (ya sea por el comienzo o por el final de la cola) como su eliminación (igualmente, desde el comienzo o final de la cola), en las que suele monitorizarse principalmente el tamaño o longitud de la cola (número de mensajes en la cola) y la antigüedad de la cola (antigüedad del mensaje más antiguo). Los mensajes son habitualmente publicados y consumidos siguiendo una filosofía FIFO (excepto para colas priorizadas).
Por defecto, una cola está localizada en el Nodo en el que ha sido declarada (al contrario que los Exchanges, que están disponibles en todos los Nodos), y referenciada por un nombre único.
Las colas proporcionan persistencia a los mensajes (de forma similar a como hace una base de datos, almacenando registros en tablas) y permiten desacoplar sistemas o componentes, facilitando buenas prácticas de diseño como el principio de responsabilidad única, la escalabilidad, o el diseño de soluciones asíncronas para el procesamiento de peticiones de larga duración, donde una solución síncrona (ej: llamadas HTTP a APIs, Web Services, etc) no resulta apropiada.
Un mensaje es una estructura de datos que está formado por tres partes:
- Cabecera (Header). Con parejas de clave/valor.
- Propiedades (Properties). Con parejas de clave/valor.
- Cuerpo (Body o Payload).
Podemos diferenciar entre Productores/Publicadores de mensajes (aquellos que añaden o envían mensajes a la cola) y Consumidores de mensaje (aquellos que leen mensajes de la cola para procesarlos y eliminarlos de la misma), cada uno de los cuales puede estar escrito en cualquier lenguaje de programación.
El hecho de que el Consumidor elimina el mensaje al confirmar (ACK) su lectura y procesamiento, es una característica importante, además de ser una de las diferencias entre RabbitMQ y Kafka (hay varias más), por poner un ejemplo. Lo vemos más en detalle, un poco más abajo.
Conceptos básicos de RabbitMQ: Exchanges, Routing Key, y Bindings
Aunque ya hemos introducido varios conceptos, como las colas, los mensajes, los productores/publicadores y los consumidores, nos quedan aún más conceptos de un message-broker como RabbitMQ, que tenemos que conocer: Exchanges, Routing Key, y Bindings.
En RabbitMQ, un Productor/Publicador no envía los mensajes directamente a una cola, en su lugar los envía a un Exchange (intercambiador de mensajes), pudiendo especificar un valor de Routing Key, de tal modo que el Exchange está enlazado (binding) con una (unicast) o varias colas (multicast) mediante bindings, enrutando los mensajes entrantes a las colas apropiadas en función del criterio correspondiente (ej: valor de la Routing Key, valores de los headers, etc.), o devolviendo un error (si no hubiera ningún binding válido para enrutar el mensaje a ninguna cola). Una vez el mensaje está en una cola (o en varias), RabbitMQ intenta entregarlo a un Consumidor «tonto» lo antes posible (push-model). A nivel de programación, en el consumidor definiremos una función callback, que se ejecutará cada vez que RabbitMQ notifique la llegada de un mensaje, que será la encargada de leer y procesar el mensaje, así como de confirmarlo (ACK).
Es decir, RabbitMQ actúa como un Middleware «inteligente» para enrutar y hacer llegar los mensajes a Consumidores «tontos» (push-model), lo que es otra diferencia frente a Kafka, el cual actúa como un Middleware «tonto» con Consumidores «inteligentes» (pull-model, donde los Consumidores son los que solicitan el mensaje).
Volviendo al tema de los Exchange (intercambiadores de mensajes), podemos diferenciar varios tipos de Exchange:
- nameless (Default Exchange ó AMQP default). Es un caso especial, creado por defecto, de tal modo que permite enrutar los mensajes entrantes a una cola, si el valor del Routing Key coincide con el nombre de la cola, y sin necesidad de que el Productor/Publicador tenga que especificar un Exchange (al utilizar el de por defecto de RabbitMQ). Está enlazado (binding) implícitamente con todas las colas, no se puede eliminar, ni se puede desenlazar (unbind) de ninguna cola. Tampoco es posible crear otro Exchange de tipo nameless (realmente, tampoco tiene sentido).
- fanout. Un mensaje entrante se enruta a todas las colas enlazadas (binding) con el Exchange, independientemente del valor del Routing Key (básicamente lo ignora).
- direct. Un mensaje entrante se enruta sólo y exclusivamente a la cola o colas enlazadas siempre y cuando al valor de la Routing Key del Mensaje coincida con el valor de Routing Key especificado en los Bindings (Binding Key).
- topic. Un mensaje entrante se enruta a una o varias colas, si el valor del Routing Key cumple un patrón (ej: Binding Key = «*.logs.error», Routing Key = «myapp.logs.error»). Para ello:
- El valor de Routing Key especificado en los Mensajes debe seguir un formato denominado Topic que consiste en una lista de palabras separadas por puntos (no puede exceder los 255 caracteres), con el fin de facilitar el uso de expresiones regulares básicas en las Binding Keys. Habitualmente sigue una nomenclatura que representa una jerarquía de palabras, comenzando con palabras más genéricas y finalizando con las más específicas.
- El valor de las Binding Key consiste en un patrón o expresión regular básica donde podemos utilizar el * para sustituir una palabra y la # para sustituir por cero o más palabras.
- headers. Un mensaje entrante se enruta a una o varias colas, en función de los valores de sus Headers (de forma similar a topic, pero ignorando el Routing Key). Es más flexible que el anterior basado en topics, ya que permite enrutar los mensaje en base a múltiples atributos (es decir, múltiples encabezados).
Para más info: RabbitMQ – AMQP 0-9-1 Model Explained
Hay más propiedades asociadas a los Exchanges, como la Durabilidad, el auto-borrado, etc.
Por defecto, una cola está localizada en el Nodo en el que ha sido declarada (al contrario que los Exchanges y los Bindings, que existen en todos los Nodos), y referenciada por un nombre único, aunque las colas se puede federar o duplicar (mirroring). Tanto los Consumidores como los Productores/Publicadores, pueden crear colas y bindings. Otro detalle importante, es que una cola consiste en un proceso Erlang.
Una cola, puede tener diferentes atributos (propiedades) que se pueden establecer y cambiar (algunos son obligatorios, y otros opcionales – los específicos del protocolo), al igual que se puede cambiar el comportamiento de la cola, de diferentes formas:
- En tiempo de creación, por ejemplo, utilizando el SDK de RabbitMQ para declarar una nueva cola.
- Mediante el uso de políticas.
Los principales atributos o propiedades de las colas, son los siguientes (hay un montón):
- Nombre de la cola: Aunque los nombres de las colas puede ser auto-generados por RabbitMQ, es recomendable especificar nosotros el nombre siguiendo un patrón (naming convention), que nos ayude en el mantenimiento (ej: asignar permisos mediante RegEx, gracias a la nomenclatura).
- Durabilidad. Representa la persistencia. Una cola transient (no durable) quedará vacía después de un reinicio, mientras que una cola durable mantendrá sus mensajes tras un reinicio.
- Auto-borrado. La cola se eliminará automáticamente cuando todos los consumidores se desconecten de ella.
- Classic ó Quorum. Una cola Classic necesita una política de Mirroring para tener alta disponibilidad, mientras que una cola Quorum tiene alta disponibilidad por defecto.
- Exclusividad. Una cola exclusiva es utilizada por una única conexión, y eliminada automáticamente cuando dicha conexión finaliza.
- Cola priorizada. Las colas son FIFO por defecto, pero también es posible crear colas Priorizadas, que permiten ordenar los mensajes teniendo en cuenta su prioridad, con el coste adicional de CPU y latencia que esto implica, y sin poder garantizar con totalidad, que los mensajes se consuman según el orden de prioridad. La Prioridad es un atributo de los mensajes.
- TTL. Permite eliminar (descartar) los mensajes existentes en la cola (no consumidos) después de un periodo de tiempo especificado, para evitar llenados que puedan acabar produciendo incidencias graves en Producción.
- Hay muchas más opciones, como Lazy Queues, Dead Letter Queues, etc.
Las colas son por defecto FIFO, principalmente desde el punto de vista del Productor/Publicador de mensajes, ya que desde el punto de vista el consumidor, para garantizar que sea FIFO se tienen que cumplir ciertas condiciones (ej: mensajes publicados a través de un único canal, utilizando un único Exchange y una única cola, y consumidos por un único canal de salida). Además, hay que tener en cuenta que un Consumidor puede rechazar un mensaje.
Ejemplo de Nomenclatura
Suele resultar útil seguir una nomenclatura (naming convention) en los objetos de RabbitMQ como colas y exchanges. Un modelo a seguir podría ser el siguiente, que define varias partes separadas por puntos: prefix.purpose.details.environment
- prefix. Permite indicar con una letra el tipo de objeto, como «q» para las colas, «ex» para los exchanges, y «b» para los bindings.
- purpose. Permite indicar el propósito, como podría ser «logs», «notify», «process», «requests», «events», etc.
- details. Permite añadir información adicional, para que el nombre del objeto sea más descriptivo.
- environment. Permite indicar el entorno, como «prod», «dev», «test», y «qa».
Un ejemplo podría ser el siguiente, para una cola, que realice notificaciones a usuarios al registrarse, en el entorno de producción: q.notify.email_user_registration.prod
Persistencia y Durabilidad de los Mensajes
En RabbitMQ es muy importante la persistencia y durabilidad de los mensajes. Para conseguirlo deben cumplirse las siguientes dos condiciones:
- La propiedad Durable de Colas (Queues) y Exchanges, debe estar configurada con el valor Durable, para que sus mensajes sean capaces de sobrevivir a un reinicio del servidor RabbitMQ. En caso contrario (si están configuradas con el valor Transient), los mensajes se perderán tras el reinicio.
- Además, los mensajes deben enviarse como Persistentes (Delivery Mode = 2 – Persistent). De este modo, son almacenados en un Log, que permitirá que sean recuperados en caso de que se reinicie el servidor RabbitMQ.
Confirmación (ACK) de los Mensajes
Cuando un Consumidor lee un Mensaje, tiene que confirmarlo (ACK), que básicamente implica decirle a RabbitMQ que el Mensaje ya ha sido leído y procesado, y que puede eliminarlo. Esto es muy importante gestionarlo de la forma correcta para no perder Mensajes que no han sido procesados, es decir.
- Cuando un Consumidor lee un Mensaje, no debería confirmarlo (ACK) hasta que lo ha procesado con éxito (evitar el auto-ACK al leer los Mensajes: primero leemos, y después de procesarlo, lo confirmamos).
- De este modo, si el Consumidor lee un Mensaje y «muere» antes de que sea procesado con éxito, el Mensaje no se perderá, RabbitMQ lo volverá a poner en la cola (re-queue), y podrá ser Consumido de nuevo más tarde.
- Si al leer un mensaje lo confirmos (ACK) al instante sin haberlo procesado, podría llegar a ocurrir que el Consumidor «muera» después de leer el Mensaje, que al haber sido confirmado (ACK) ha sido eliminado de RabbitMQ, por lo que finalmente nunca llegará a ser procesado con éxito.
- Por defecto, existe un timeout de 30 minutos para la confirmación (ACK) de los mensajes. Es decir, si leemos un Mensaje y tardamos más de 30 minutos en confirmarlo, RabbitMQ cerrará el canal (Channel) de dicho Consumidor generando una Excepción, y volviendo a poner en la cola (re-queue) los mensajes afectados. Es posible aumentar o reducir este timeout, a través del fichero de configuración de RabbitMQ (rabbitmq.conf), ajustando la propiedad
consumer_timeout, tal y como se muestra en el siguiente ejemplo:
# one hour in milliseconds
consumer_timeout = 3600000La correcta gestión de la confirmación (ACK) de los Mensajes, es algo que hay que gestionar habitualmente en el código fuente de las aplicaciones (excepto que se quiera ajustar el timeout en el rabbitmq.conf para extenderlo o reducirlo), y que si no se hace bien, nos podría suponer algún pequeño susto.
Colas Temporales
Tanto Productores como Consumidores, pueden crear colas, intercambiadores de mensajes (Exchanges), bindings, etc, no sólo es cuestión de enviar y recibir Mensajes, que también lo hacen. Esto es un detalle muy importante, ya que permite escenarios en los que un Productor crea (declara) un Exchange, y cada Consumidor que desea recibir los mensajes, crea (declara) su propia cola y los bindings necesarios, lo que facilita la implementación de patrones de publicación y suscripción, por poner un ejemplo.
Otro detalle importante, y directamente relacionado con lo anterior, es que un Consumidor puede crear (declarar) una cola con un nombre aleatorio y de uso exclusivo (utilizada por una única conexión, y eliminada automáticamente cuando dicha conexión finaliza), con lo que estaremos creando una cola temporal. Esta técnica es útil al implementar patrones de publicación y suscripción, ya que el único interesado en la cola es el propio Consumidor que la declara (por lo tanto no es relevante que tenga un nombre bien definido y conocido por otros procesos), y cuando acabe de usarla y cierre la conexión se puede eliminar y liberar recursos.
El uso de colas temporales es una técnica interesante, no siempre es necesario que las colas, bindings, y exchanges sean creados previamente por un administrador, también es muy interesante esta auto-gestión que minimiza el coste de mantenimiento y además facilita la implementación de ciertos patrones y soluciones.
Instalación de RabbitMQ en Ubuntu 22 (Single Node)
A continuación vamos a explicar la instalación de RabbitMQ en Ubuntu paso a paso. Para ello voy a utilizar una Máquina Virtual en Hyper-V con Ubuntu 22, a la que inicialmente la voy a asignar 1 core y 2 GB de RAM, de momento más que suficiente.
Lo primero, actualizamos el sistema operativo, e instalamos algunas utilidades que necesitaremos (wget, curl, vim, gnupg, etc).
sudo apt update -y && sudo apt upgrade
sudo apt-get install wget curl vim gnupg apt-transport-https software-properties-common lsb-release -ySeguidamente instalamos Erlang.
sudo add-apt-repository ppa:rabbitmq/rabbitmq-erlang
sudo apt update
sudo apt install erlangA continuación vamos a instalar RabbitMQ con los paquetes de PackageCloud.
curl -s https://packagecloud.io/install/repositories/rabbitmq/rabbitmq-server/script.deb.sh | sudo bash
sudo apt update
sudo apt install rabbitmq-server -yLa instalación creará varias cosas, entre ellas:
- Un usuario rabbitmq
- Un directorio /etc/rabbitmq donde podamos almacenar los ficheros de configuración de RabbitMQ
- Un directorio /usr/lib/rabbitmq donde están lo binarios, incluyendo el utilizado por el servicio/demonio y la interfaza de comandos de RabbitMQ con la que podremos realizar diferentes tareas adminitrativas.
- Un directorio /var/log/rabbitmq donde dejará los logs
- Un servicio o demonio rabbitmq-server, al arrancar además proporcionará la API RESTful de RabbitMQ, con la que podremos hacer multitud de tareas, así como integrarnos con otros sistemas.
Además, por defecto RabbitMQ utilizará los siguientes puertos:
- tcp-5672. Utilizado para el protocolo AMQP, se utiliza para la entrada de mensajes.
- tcp-25672. Utilizado para la comunicación interna en un Cluster de RabbitMQ.
- tcp-15672. Utilizado para el acceso a la API RESTful de RabbitMQ, así como a la Consola de Gestión, en caso de estar instalada.
Podemos comprobar que el servicio de RabbitMQ ha sido instalado y arrancado con éxito, con un comando como el siguiente.
systemctl status rabbitmq-serverHabilitamos la Consola de Gestión, que escucha en el puerto tcp-15672 a través de HTTP. Como por defecto se incluye un usuario guest (con contraseña guest) que sólo puede conectar desde localhost, crearemos también un usuario adminitrador desde línea de comandos a través de la CLI de rabbitmqctl.
sudo rabbitmq-plugins enable rabbitmq_management
sudo rabbitmqctl add_user admin StrongPassword
sudo rabbitmqctl set_user_tags admin administrator
sudo rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"Es una buena práctica eliminar el usuario guest (por defecto es admin, y su password es guest, lo que lo convierte en una vulnerabilidad grave), o al menos cambiarle la contraseña (que no sea la de por defecto). De momento no lo vamos a hacer, ya que para un entorno de laboratorio y pruebas esto no es un problema, pero es algo a tener en cuenta. Se puede hacer más adelante, desde la Consola de Gestión de RabbitMQ o desde línea de comandos.
El comando rabbitmqctl, nos permite hacer bastantes cosas más desde línea de comandos, a continuación os muestro algunos ejemplo a modo ilustrativo.
sudo rabbitmqctl list_queues
sudo rabbitmqctl list_exchanges
sudo rabbitmqctl list_bindingsPodemos comprobar el acceso a la API RESTful de RabbitMQ haciendo un GET con un navegador a un Endpoint como el de Nodes. Hay que tener en cuenta que el acceso a esta API está protegido con autenticación básica, podremos utilizar el usuario admin que acabamos de crear.

También podemos acceder a la documentación de la API RESTful de RabbitMQ, que nos será de gran ayuda en caso de tener que utilizar dicha API.
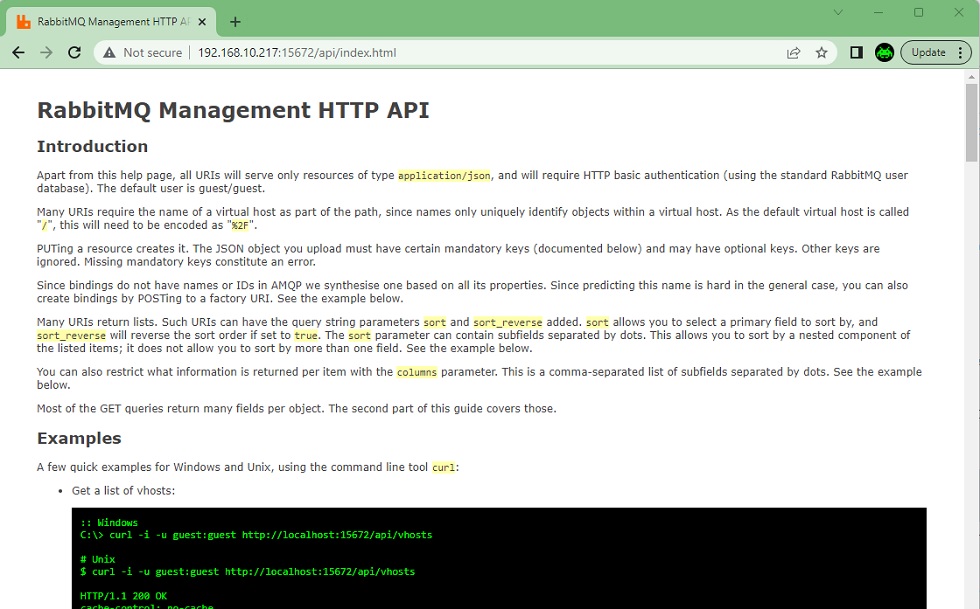
La configuración de RabbitMQ, puede realizarse de varias formas:
- Mediante variables de entorno.
- Mediante fichero de configuración. Por defecto RabbitMQ no incluye ningún fichero de configuración, deberemos crearlo nosotros desde cero, o bien descargar uno de ejemplo desde GitHub y modificarlo (opción preferente): GitHub – rabbitmq.conf
- Mediante parámetros y políticas definidos en tiempo de ejecución a través de la Consola de Gestión, comandos o API.
Instalación de RabbitMQ con Docker
Una forma más rápida y sencilla de ejecutar RabbitMQ es utilizando Docker: Docker Hub – RabbitMQ
Si sólo deseamos realizar una prueba rápida, basta con ejecutar el siguiente comando docker, y tenemos RabbitMQ arrancado en local sobre los puertos por defecto (tcp-5672 y tcp-15672), sin almacenamiento persistente (sin volúmenes), disponible para usarlo con las credenciales por defecto de guest/guest. Super fácil. Si en lugar de la versión 3.11.11 deseas otra, basta con especificar la versión en la imagen Docker, y listo (ej: 3.11.13-management). Además, las imágenes docker que acaban en *-management ya vienen con la Consola de Gestión habilitada, listas para usar.
docker run -d --name rabbitmq -p 15672:15672 -p 5672:5672 rabbitmq:3.11.11-management
Cuando acabemos, lo podemos parar y eliminar rápidamente. Con docker rm eliminaremos completamente el contenedor.

Si queremos hacer un uso un poco más serio, podemos utilizar Docker, pero deberíamos usar volúmenes. Esto resulta especialmente fácil utilizando un Docker Compose, donde podemos definir rutas relativas, que facilita mucho las cosas.
Para ello, podemos utilizar el siguiente Docker Compose que os comparto en GitHub: GitHub – ElWillieES – Rabbit Docker Lab
Nos descargamos el repo (git clone), y arrancamos RabbitMQ con Docker Compose (docker-compose up -d). Super fácil.

Introducción a la Consola de Gestión de RabbitMQ
Aunque RabbitMQ proporciona una API RESTful y una interfaz de línea de comandos, con las cuales podemos administrar nuestro servicio de RabbitMQ, es muy habitual instalar la Consola de Gestión de RabbitMQ para hacernos la vida más fácil, que básicamente consiste en activar un Plugin, o en el caso de Docker, utilizar la imagen que incluye la Consola de Gestión ya pre-instalada.
Sin duda, la Consola de Gestión de RabbitMQ es el Plugin más usado, y será en la mayoría de casos un gran compañero de viaje. Vamos a acceder a la Consola de Gestión de RabbitMQ e intentar inicia sesión con el usuario admin que acabamos de crear. En mi caso, he instalado RabbitMQ en una máquina virtual Ubuntu, por lo que utilizaré en la URL la dirección IP de dicha máquina y el puerto por defecto (tcp-15672).
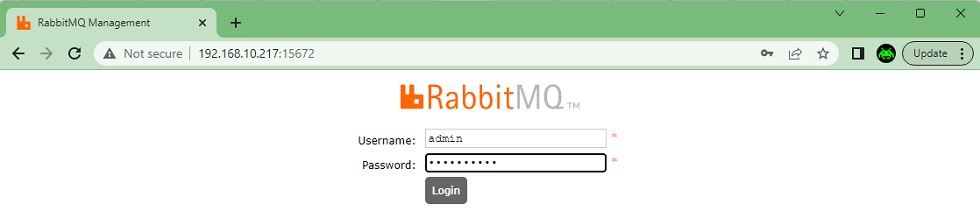
Veremos que la Consola de Gestión de RabbitMQ está organizada en varias pestañas. Vamos a verlas, para que tengamos una idea de todas ellas, aunque no entremos a todo el detalle.
En la pestaña Overview podremos encontrar una visión global del Cluster de RabbitMQ, y ver cosas como lo siguiente:
- Estadísticas globales (Totals). En nuestro caso aparece vacío, ya que que acabamos de realizar la instalación y aún no tenemos carga de trabajo (ni colas, ni publicadores, ni consumidores).
- Información de los diferentes nodos del Cluster (Nodes), en nuestro caso tenemos un único nodo (rabbit@rabbitmq01), que acabamos de instalar. Importante que lo que vemos en verde, esté en verde (si sale algo en rojo, malo). Podemos hacer click sobre el nombre del nodo para mostrar estadísticas detalladas de ese Nodo en concreto (ej: file descriptors, socket descriptors, procesos Erlang, memoria, espacio en disco, Erlang Virtual Machine, y un montón de estadísticas más, especialmente importante Memory details, en la parte inferior de la página).
- En Churn statistics podemos ver estadísticas de operaciones (conexiones, canales y colas).
- En Ports and contexts tenemos el detalle de los puertos TCP utilizados (por defecto tcp-5672, tcp-25672, tcp-15672) y contextos Web (por defecto / para RabbitMQ Management).
- Mediante Export definitions podemos exportar a un fichero JSON gran parte de la configuración (ej: usuarios, vhosts, colas, exchanges, etc), de tal modo que mediante Import definitions podamos importalo en el mismo o en otro servidor. Esto está muy bien, si tenemos que hacer una migración, y en otros casos, también resulta de gran utilidad.

En la pestaña Connections podemos ver el detalle de las conexiones tcp/ip establecidas por los clientes contra RabbitMQ, indicando el usuario (ej: guest, admin, o el que sea), estado (ej: running, flow, idle, blocking/blocked), el uso de SSL/TLS, el número de canales abiertos por la conexión (cada conexión puede abrir uno o varios canales), etc. Una conexión está en estado Flow, cuando se están enviando datos demasiado rápido a RabbitMQ, de tal modo que RabbitMQ frena intencionadamente el procesamiento de mensajes de dicha conexión incrementando la latencia en su respuesta, para protegerse así de ataques de denegación de servicio (DoS). Si la situación continúa y la conexión intenta enviar demasiados datos, RabbitMQ bloquearía la conexión (estado blocking/blocked) deteniendo el procesamiento de mensajes. Además, podemos hacer click en una conexión para ver más detalles de dicha conexión incluso cerrarla. En nuestro caso, que acabamosde instalar RabbitMQ, aparecerá vacío (sin conexiones).
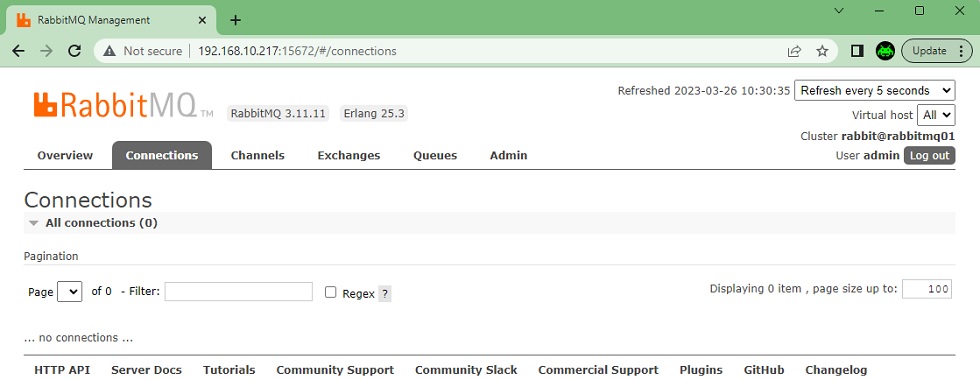
En la pestaña Channels podemos ver el detalle de cada canal y su relación con la correspondiente conexión tcp/ip de un cliente, teniendo en cuenta que cada conexión tcp/ip de un cliente, puede abrir uno o varios canales (conexiones virtuales dentro de una única conexión tcp/ip, lo cual es más eficiente que tener que establecer múltiples conexiones tcp/ip). En esta pantalla incluso podremos cerrar conexiones y/o canales. En nuestro caso, que acabamos de instalar RabbitMQ, aparecerá vacío (sin canales ni conexiones).
En la pestaña Exchanges (intercambiadores de mensajes) podemos ver el detalle de cada Exchange, así como crear nuevos. Podemos hacer click en cualquiera de ellos, para ver sus propiedades en detalle y ejecutar acciones como eliminarlo o publicar un mensaje. En nuestro caso, que acabamosde instalar RabbitMQ, sólo aparecen los Exchanges internos de RabbitMQ, que no podemos eliminar ni modificar (sólo utilizarlos).

En la pestaña Queues podemos ver el detalle de las colas existentes definidas en RabbitMQ, así como crear nuevas colas o eliminarlas. No es posible modificar una Cola existente, es decir, si por error hemos creado una cola sin Persistencia (Durability = Transient), deberemos crear otra, en todo caso eliminarla y volverla a crear de la forma correcta. En nuestro caso, que acabamosde instalar RabbitMQ, estará vacío (no existe ninguna cola aún). Si tuviéramos Colas, las veríamos junto con un conjunto básico de estadísticas (ej: mensajes disponible, mensajes leídos sin confirmar, estado, etc.), y podríamos acceder al detalle de cada una.
En la pestaña Admin podemos administrar Usuarios, Virtual Hosts, Feature Flags, Policies, Limits, así como modificar el nombre del Cluster. Esto implica tanto poder ver el detalle de la configuración de todos estos elementos, así como realizar acciones diversas (creación/modificación/eliminación).
Ejemplo básico de creación y uso de colas en RabbitMQ: Patrón «Simple Queue»
A continuación vamos a realizar un ejemplo básico de creación y uso de colas en RabbitMQ, que a modo divulgativo, ayude a comprender su funcionamiento y a familizarizarse con la Consola de Gestión. Vamos a simular el Patrón «Simple Queue» utilizando la Consola de Gestión de RabbitMQ, que es el más sencillo. Existen varios Patrones que intentan resolver diferentes casos de uso, y que podemos ver en el siguiente Post.
Lo primero que necesitaremos es crear una cola, algo que podemos hacer desde la pestaña Queues de la Consola de Gestión de RabbitMQ. Importante especificar al menos las siguientes opciones (hay más opciones posibles, pero con esas es suficiente para este primer ejemplo), click Add queue, y hemos creado nuestra primera cola:
- Tipo (ej: classic)
- Nombre (ej: q.logs.example.dev conforme a la nomenclatura que comentábamos antes)
- Durabilidad (durable = que sea persistente)
- Auto-borrado.

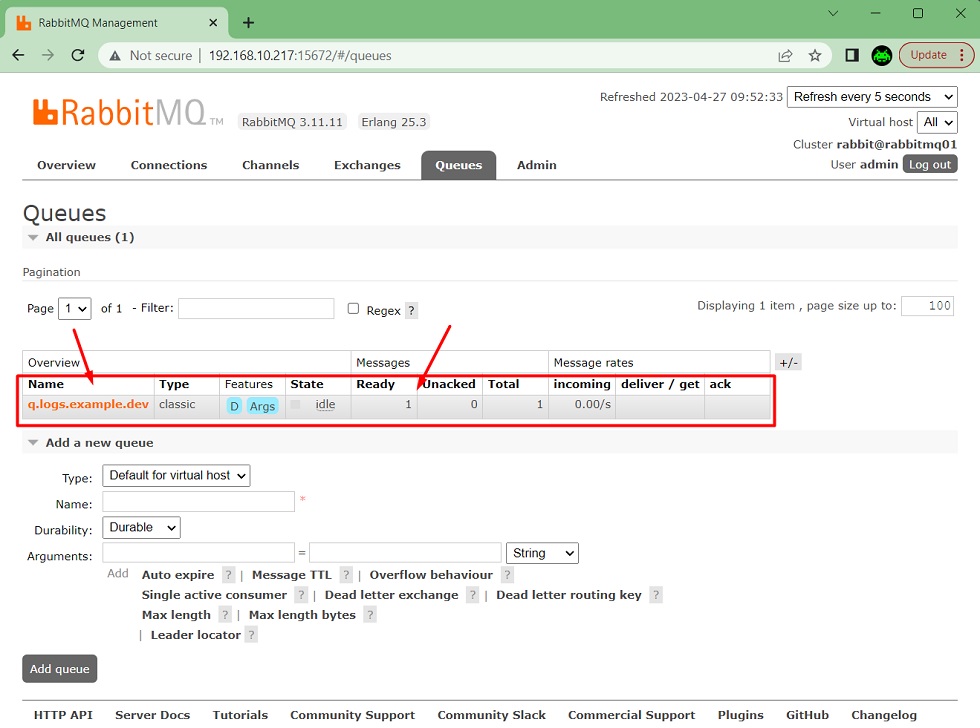
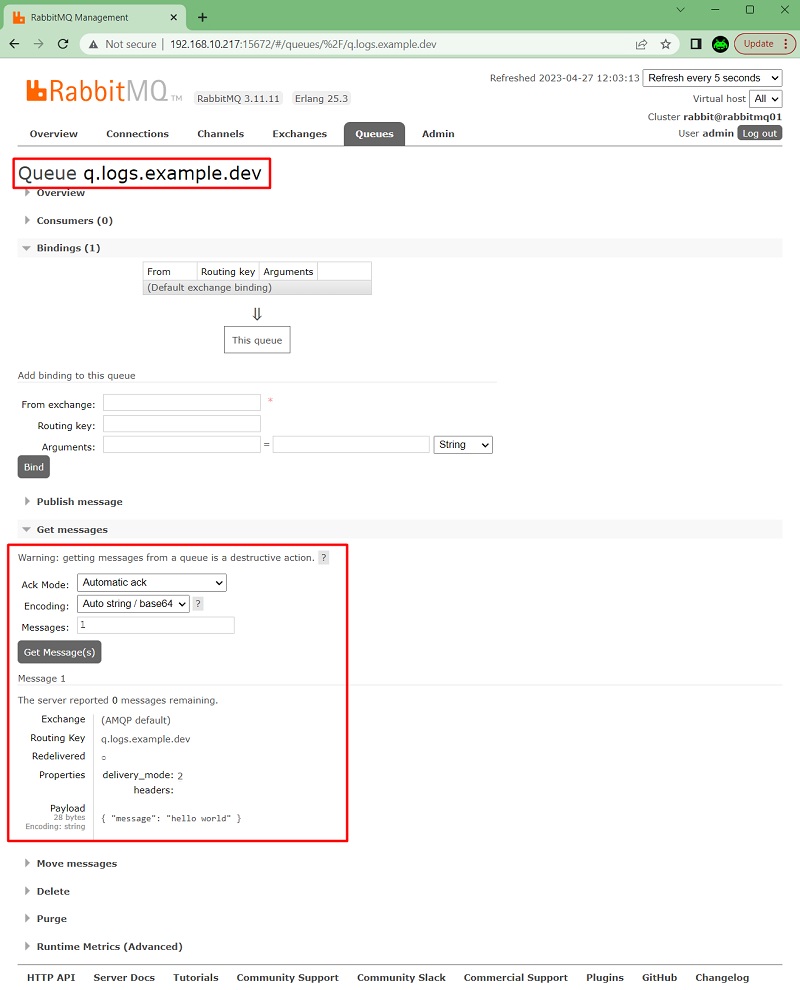
Una vez creada la cola q.logs.example.dev, podremos ver unas estadísticas básicas de la misma (y del resto de colas que pudiéramos tener), aunque de momento veremos que está vacía. Haremos click en el nombre de la cola, para acceder a sus detalles y enviar nuestro primero mensaje.

En la página de la cola q.logs.example.dev, podemos ver muchos más detalles de la cola (ej: varias estadísticas, bindings, etc), así como realizar ciertas acciones (ej: añadir bindings, publicar mensajes, etc.). En nuestro caso, lo que nos interesa es enviar un mensaje a la cola como si fuéramos un Publicador o Productor, algo que podemos hacer desde la sección Publish message. Para nuestro ejemplo, simplemente especificaremos que deseamos enviar un mensaje persistente (que sobreviva a los reinicios) así como el cuerpo del mensaje (puede ser cualquier valor, texto plano, un XML, un JSON, lo que queramos), y click en Publish message. Un detalle importante, en línea con lo que hablábamos antes al explicar las colas y los exchanges: realmente, no estamos publicando el mensaje directamente sobre la cola, sino sobre el default exchange (nameless exchange), usando como valor de routing key el propio nombre de la cola.

Si volvemos a la pestaña Queues, podremos ver que tenemos un mensaje disponible en la cola. Para intentar leerlo, de nuevo, hacemos click en el nombre de la cola.
En la página de la cola q.logs.example.dev, podemos leer mensajes desde la sección Get messages, como si fuéramos un Consumidor. Para ello, deberemos especificar lo siguiente, y click en Get Message(s), lo cual nos devolverá el mensaje, incluyendo la Routing Key, el valor de delivered, las Properties, y el número de bytes del Payload, además del propio Payload (el mensaje en sí):
- Modo de ACK. En nuestro caso de ejemplo elegiremos «Automatic ACK» para leer el mensaje confirmándolo y eliminándolo de la cola, tal y como haría habitualmente un Consumidor, pero también tenemos otras opciones, por ejemplo «NACK message requeue true» (opción por defecto) nos permitiría leer el mensaje devolviéndolo a la cola en la misma posición o lo más cerca posible (sin eliminarlo) pero marcado como redelivered=true. De este modo, si necesitamos ver uno o varios mensajes de la cola sin perderlo para depurar una incidencia, podríamos hacerlo, sin perder el mensaje.
- Encoding. Podemos elegir entre Base64 y Auto, en nuestro caso lo dejaremos en Auto para este ejemplo.
- Número de Mensajes. Sí sólo deseamos leer un único mensaje como en nuestro ejemplo, pues 1, y listo.
Despedida y Cierre
Hasta aquí llega este primer Post de RabbitMQ, una herramienta fundamental para el desarrollo de soluciones asíncronas mediante uso de colas, que podemos utilizar de forma gratuita en nuestros Proyectos. RabbitMQ actúa como un Middleware «inteligente» capaz de enrutar y hacer llegar los mensajes a un Consumidor «tonto» (push-model).
Hemos visto una introducción o resumen para comprender en qué consiste RabbitMQ (ej: Productores, Consumidores, Colas, Exchanges, Routing Keys, Bindigs, etc.), hemos visto la Consola de Gestión y sus principales pantallas para comprender cómo nos puede ayudar en el día a día (aunque RabbitMQ también proporciona una API y una línea de comandos), hemos visto cómo instalar RabbitMQ en Ubuntu, Docker, y Docker Compose, y también hemos realizado un ejemplo básico de creación y uso de colas usando la Consola de Gestión. Además hemos compartido un repo de GitHub con un Docker Compose para que podáis hacer pruebas de forma rápida y sencilla (GitHub – ElWillieES – RabbitMQ Docker Lab).
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.