
Nova es el Servicio de Compute (una especie de Hypervisor Manager), uno de los servicios más importantes y originales de OpenStack, a través del cual podemos gestionar todos lo Hypervisors así como el ciclo de vida de nuestras Instancias de OpenStack (ej: creación, snapshots, borrado, etc.), incluyendo la segregación y agrupamiento de Hosts en Regiones, Host Aggregates, y Availability Zones, la definición de Flavors para la gestión de tallas de los recursos (CPU, Memoria, Disco), y mucho más, totalmente integrado en el Dashboard y accesible a través de API y de OpenStack CLI
Continuando con la serie de Posts sobre OpenStack, después de que tratáramos hace unos días cómo instalar OpenStack en CentOS 7 con PackStack así como un breve introducción a OpenStack, viéramos una introducción al Dashboard y CLI de OpenStack, y conociéramos el Servicio de Identidad (Keystone), el Servicio de Imágenes (Glance), y el Servicio de Red (Neutron), ahora le toca el turno al servicio de Compute (Nova), el encargado de proporcionarnos el músculo (la capacidad de procesamiento, es decir, la CPU y la Memoria donde corren nuestras máquinas virtuales – Instancias). Comenzamos.
Introducción a Nova
El Servicio de Compute (Nova) es quizás el más importante de OpenStack, y uno de los dos servicios originales (junto a Swift). Permite gestionar grandes pooles de máquinas donde poder ejecutar Instancias (máquinas virtuales), soportando gran variedad de Hypervisors (ej: QEMU/KVM, VMWare, Hyper-V, Xen, LXC, UML, etc.) incluso servidores físicos (Bare Metal). Es un servicio distribuido que se ejecuta en todos los Nodos Hypervisors, escalable horizantalmente, que permite la gestión del ciclo de vida de las Instancias, y gestionable de forma sencilla por los usuarios y administradores a través de una API, del Dashboard, y de OpenStack CLI. Podríamos ver a Nova como el Hypervisor Manager de OpenStack, capaz de hablar con los Hypervisors a traves de una API o de un Agente.
Nova utiliza Key Pairs para facilitar la autenticación en las Instancias de forma segura sin uso de contraseñas (habitualmente los usuarios root están deshabilitados por seguridad), para lo cual injecta las claves en la Instancia a través del proceso de cloud-init. Los usuarios y adeministradores de OpenStack pueden gestionar los Key Pairs a través del Dashboard o de OpenStack CLI.
A continuación se puede ver un par de diagramas de arquitectura de Nova, según el tipo de red que se use:
- La red de Nova, antiguo servicio de red Legacy de OpenStack.
- La red de Neutron, solución actual y más avanzada de red en OpenStack. ZeroMQ. Requiere que los Agentes de OVS (Open vSwitch) y Linux Bridge se ejecuten en los Nodos de Nova.
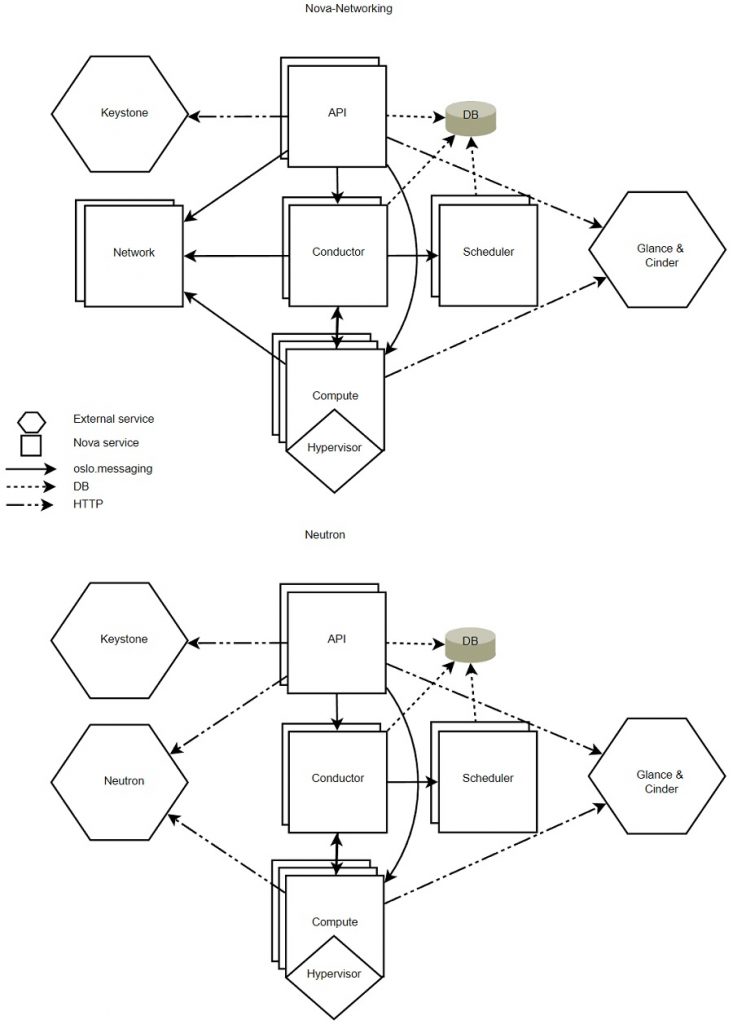
La comunicación de los usuarios con Nova es a través de la API, mientras que la comunicación entre los diferentes componentes de Nova es mediante mensajes RPC con oslo.messaging (una librería que hace de capa de abstracción de las colas de mensaje como RabbitMQ o cualquier otro sistema AMQP como Apache Qpid o ZeroMQ). Además de la API, tendremos Nodos de Compute (Hypervisors), el Scheduler (se encarga por ejemplo de decidir en que Nodo de Compute arrancar una nueva Instancia, en base a filtros y pesos), etc.
Nova se relaciona con varios componentes Core de OpenStack, como el Servicio de Identidad (Keystone), el Servicio de Imágenes (Glance), o el Servicio de Red (Neutron). Para poder crear una nueva Instancia en Nova, necesitamos al menos:
- Una Imagen pre-construida de Glance, que se utilizará para arrancar (boot) la Instancia.
- Una red, a la que conectaremos nuestra Instancia para que tenga conectividad con los recursos que necesite para su funcionamiento.
- Debemos seleccionar una Flavour, que básicamente define los recursos básicos de nuestra máquina (RAM, CPU y Storage). Nova incluye un conjunto de Flavours por defecto al instalar OpenStack, que podemos personalizar o crear nuevos con libertad.
- Opcionalmente podemos atachar un Volumen de Cinder para proporcionar almacenamiento persistente.
Agrupando Nodos de Compute
Según vaya creciendo nuestra instalación de OpenStack, necesitaremos poder agrupar o segregar nuestros Nodos de Compute, principalmente por dos motivos:
- Agrupamiento en base a la ubicación, como el Data Center, la Región geográfica, el Rack, las fuentes de alimentación, etc. Esto es útil para construir sistemas de alta disponibilidad, ya que de este modo, podríamos tener nuestras Instancias distribuidas para ser menos tolerantes a fallos.
- Agrupamiento en base a los recursos HW, como la disponibilidad de GPU, de tarjetas de red rápidas, almacenamiento SSD de alto rendimiento, tipos de procesadores (Intel, AMD, ARM, etc), etc. Esto es útil para poder utilizar en cada caso el HW que necesitemos, y así poder optimizar el uso de nuestros recursos, y en consecuencia, el rendimiento y el coste.
Para poder realizar esta agrupación o segregación de Nodos, OpenStack nos proporciona los siguientes mecanismos.
- Regiones. Cada Región tiene una implementación completa de OpenStack, con su propia API, Storage, Network, Compute, etc. Habitualmente, sólo Keystone y Horizon son compartidos entre las diferentes Regiones, para poder ofrecer un Servicio de Identidad y Dashboard unificado entre Regiones. Por defecto, todos los recursos pertenecen a la Región por defecto, y los usuarios tienen que especificar en qué Región desean crear un nueva Instancia.
- Host Aggregates. Permite agrupar Nodos en base a los metadatos y Flavours. Los metadatos permiten describir características de los Nodos como por ejemplo disponibilidad de GPU, de almacenamiento SSD, NICs de alto rendimiento, etc. Podemos crear un Host Aggregate en base a los metadatos (parejas de clave-valor) y también asociar metadatos a los Flavours, ya que los usuarios sólo seleccionan un Flavour al crear una Instancia (no tiene que especificar qué Host Aggregate desea). De esta forma, también se permite que un Nodo pueda pertenecer a sólo uno o a varios Host Aggregates.
- Availability Zones. Un concepto similar a Host Aggregates (realmente es un caso especializado de Host Aggregate, y se utiliza el mismo comando openstack aggregate), inspirado en AWS. Permite agrupar Nodos en base a su geolocalización (Data Center, Rack, etc), red, o fuentes de alimentación, con el propósito de definir dominios de fallo, de tal modo que podamos repartir nuestras Instancias entre ellos para garantizar la disponibilidad de nuestro servicio. Al contrario que ocurría con Host Aggregates, los usuarios al crear una Instancia deberán especificar el Avalibility Zone. En el caso de los Availability Zones, un Nodo sólo puede pertenecer a un único Availability Zone.
Nova y la CLI
Ya vimos en el anterior Post sobre el Dashboard de OpenStack, como realizar varias tareas en OpenStack a través del Dashboard incluyendo algunas relacionadas con Nova, y en general resulta bastante intuitivo. Ahora vamos a ver cómo trabajar con Nova desde OpenStack CLI.
Para comenzar, vamos a cargar las variables de entornos de OpenStack para conectarnos como admin, para listar los servicios y estado de Nova. Seguidamente, listaremos los flavor existentes, y crearemos uno aún más pequeño que el menor de los que vienen por defecto en OpenStack. Todo esto, lo haremos con los siguientes comandos.
source keystonerc_admin
openstack compute service list
openstack flavor list
openstack flavor create --id 1001 --ram 256 --disk 5 --public m1.tinier
openstack flavor list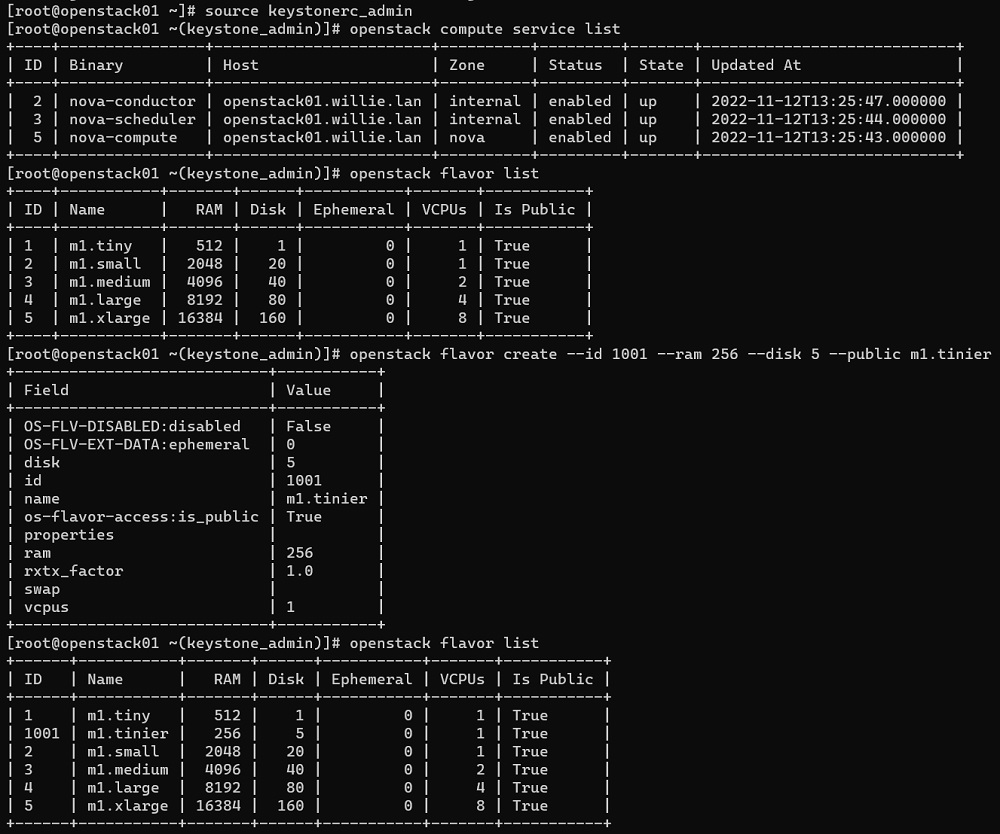
Lo siguiente que vamos a hacer es crear una nueva Instancia en OpenStack, utilizando el flavor que acabamos de crear. Para ello, primero creamos las Claves SSH, listamos las Imagenes y redes para ver cuáles nos van a hacer falta, y finalmente creamos la nueva Instancia.
openstack keypair create willie-keypair > willie-keypair.key
cat willie-keypair.key
openstack image list
openstack network list
openstack server create --image cirros-0.5.1-x86_64 --key-name willie-keypair --flavor 1001 --nic net-id=7b82b593-2d84-43f2-b115-b5abcc170c31 cirros02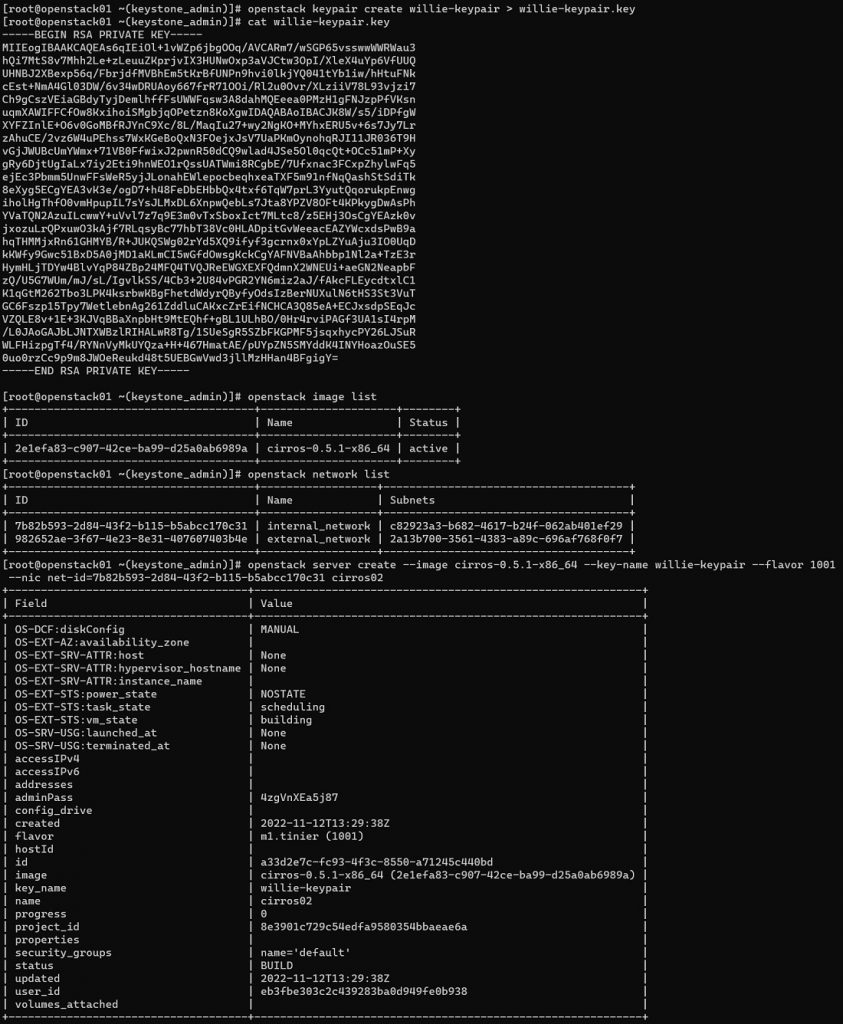
Ahora que tenemos levantada nuestra Instancia, a través de OpenStack CLI podemos obtener la URL a la Consola de la Instancia (para poder logarnos, entrar, e iteraccionar con la Instancia), así como también podemos consultar los Logs de la Instancia (especialmente útil cuando tenemos problemas durante el arranque).
openstack console url show --novnc cirros02
openstack console log show cirros02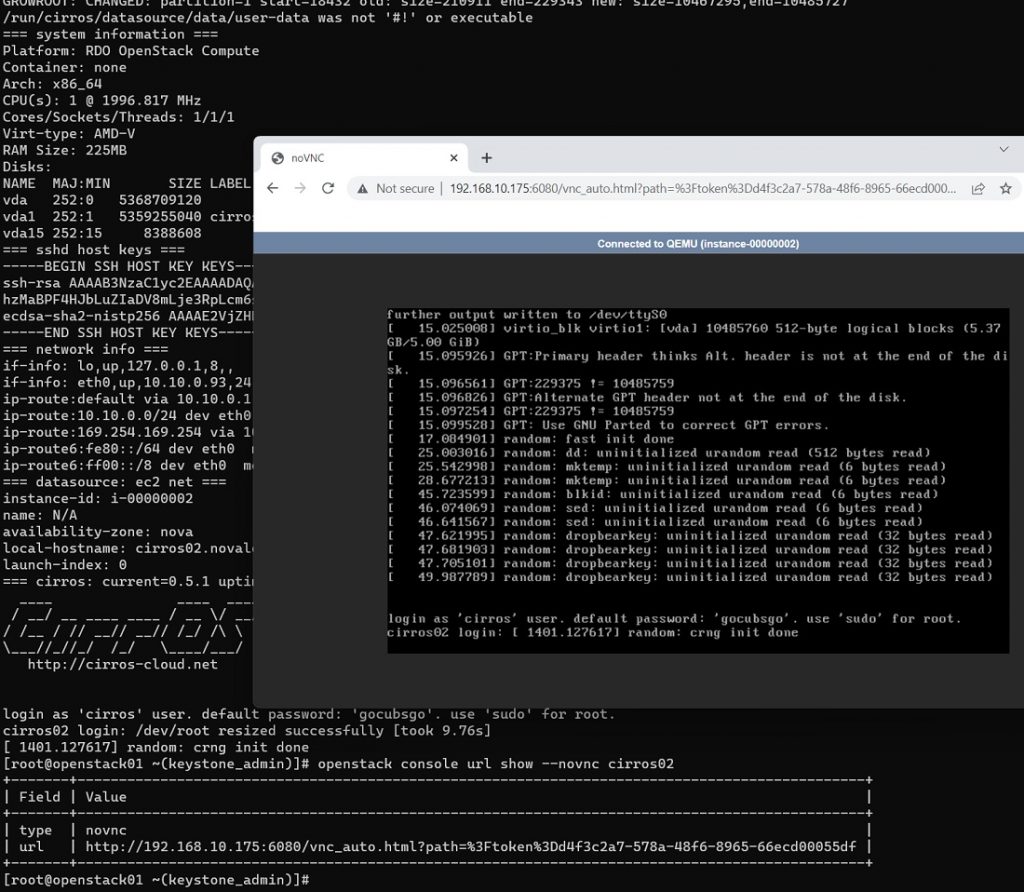
En nuestro caso de ejemplo, tenemos un laboratorio formado por un único servidor (all-in-one), pero en un entorno real de Producción tendremos fácilmente decenas o centenas de servidores, por lo que Nova debe decidir en que servidor arrancar una Instancia, mediante un proceso de filtrado (selección) y pesos (priorización) de los servidores disponibles.
head /etc/nova/nova.conf
cat /etc/nova/nova.conf | grep filter
cat /etc/nova/nova.conf | grep weightPara continuar, vamos a crear un Snapshot de nuestra Instancia. Realmente, al crear un Snapshot, realmente estamos creando una nueva Imagen en Glance, lo que nos permite poder arrancar una nueva Instancia desde el Snapshot, de una forma muy sencilla.
openstack server image create --name snap-cirros02-20221112 cirros02
openstack image listAhora vamos a ver un ejemplo de como crear un Hot Aggregate en base a una propiedad, para identificar máquinas con almacenamiento SSD, así como añadir un Nodo al Host Aggregate, y asociar esa misma propiedad a un Flavor, para que cuando un usuario cree una nueva Instancia con dicho Flavor, se pueda hacer el match y utilizar el Nodo apropiado.
openstack aggregate create ssd-nodes
openstack aggregate set --property ssd=true ssd-nodes
openstack aggregate add host ssd-nodes openstack01.willie.lan
openstack flavor set --property ssd=true m1.large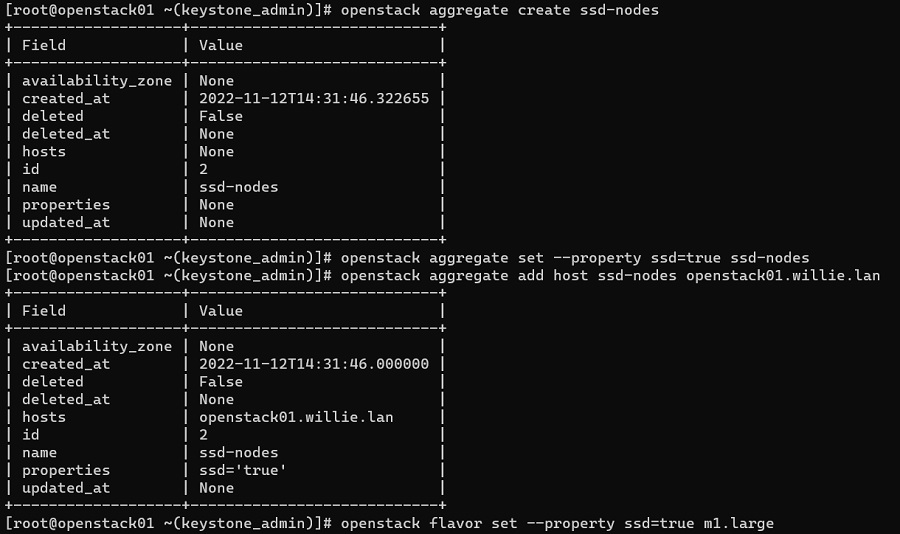
Despedida y Cierre
Hasta aquí llega este Post de OpenStack, en el que hemos podido entrar a ver en más detalle el Servicio de Compute (Nova), uno de los más importantes y de los originales de OpenStack, a través del cual podemos gestionar todos lo Hypervisors así como el ciclo de vida de nuestras Instancias de OpenStack (ej: creación, snapshots, borrado, etc.), incluyendo la segregación y agrupamiento de Hosts en Regiones, Host Aggregates, y Availability Zones, a través de varios ejemplos realizados con OpenStack CLI.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.