
Redis Cluster proporciona escalabilidad horizontal, al dividir los datos que tenemos en Redis entre varios nodos (Shards) entre los que se repartiran las claves a almacenar. De este modo, aunque alcancemos el límite de recursos de nuestra máquina, podremos seguir creciendo a base de añadir más nodos (escalado horizontal), donde cada nodo almacena y se responsabiliza sólamente de una parte de las claves (un conjunto de slots). Además, se puede combinar con la Replicación, consiguiendo una gran escalabilidad (horizontal y vertical) y alta disponibilidad, pero… sólo podremos utilizar db0, cambiará la forma de conectar, aumentará el coste de mantenimiento (razón para pensar en Redis en Cloud), y asumiremos algunas limitaciones relacionadas con comandos que actúan sobre varios slots.
Continuando con nuestra serie sobre Redis, tras haber hablado recientemente sobre cómo instalar y configurar Redis en Ubuntu, sobre los mecanismos de persistencia y durabilidad en Redis, y sobre la Replicación (1 Master + N Slaves) y el Automatic Failover son Sentinel, llega el momento de hablar acerca de Redis Cluster y las escalabilidad con Redis.
Cuando hablamos de escalabilidad se suele diferenciar principalmente dos tipos:
- Escalado Vertical (scaling up). Consiste en añadir más recursos (ej: memoria, CPU, etc.) al servidor o servidores existentes, para poder soportar más carga. En algún momento alcanzaremos un límite, a partir del cual no podremos añadir más recursos.
- Escalado Horizontal (scaling out). Consiste en añadir más servidores para poder soportar mejor la carga, y puede combinarse con el escalado vertical.
Mediante la Replicación de Redis y el uso de Sentinel para el Automatic Failover, conseguimos obtener principalmente un escalado Vertical ampliando los recursos de nuestra máquina, y si somos capaces de conectarnos a las réplicas para consultas de lectura, tendríamos en cierto modo un escalado horizontal a base de añadir más réplicas, aunque sin poder escalar el maestro, y con el problema de que podemos alcanzar el techo de los recursos de la máquina, lo que nos impediría poder crecer más.
Redis Cluster proporciona una mayor escalabilidad, al permitir dividir los datos que tenemos en Redis entre varios servidores organizados en Shards o Node Groups (cada Shard o Node Group lo forma un maestro y sus réplicas) entre los que se repartiran las claves a almacenar (a diferencia de la Replicación que mantiene una copia de lectura completa con todas las claves en una o varias réplicas). De este modo, aunque alcancemos el límite de recursos de nuestra máquina, podremos seguir creciendo a base de añadir más nodos (escalado horizontal), donde cada nodo almacena y se responsabiliza sólamente de una parte de las claves (lo que se llama un slot). Además, se puede combinar con la replicación, consiguiendo una gran escalabilidad (horizontal y vertical) y alta disponibilidad. Dado que Redis es una solución single-thread, el escalado horizontal ofrece una capacidad de crecimiento lineal.
El siguiente gráfico, de la página oficial de Redis, resume las diferentes alternativas: una base de datos standalone, replicación, Redis Cluster, y Redis Cluster con replicación.
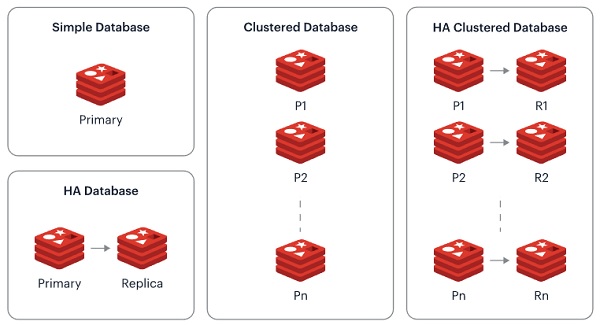
Al igual que ocurre con Sentinel, para poder utilizar un Redis Cluster necesitaremos utilizar una librería que lo soporte (que sea cluster-aware) para conectarnos en modo Cluster, ya que si nos conectamos un servidor Redis del Cluster, sólo tendremos visibilidad de las claves almacenadas en el mismo, pero no del resto (es decir, tendremos acceso sólo a una parte de todas las claves, y eso no es lo que queremos).
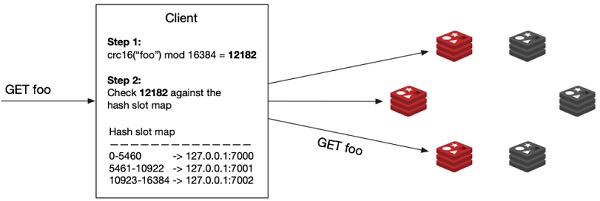
Redis Cluster organiza todo su espacio de memoria entre 16384 slots, de tal modo que cada Shard (recordemos que un Shard lo forma un maestro y sus réplicas) se encargará de almacenar y gestionar un conjunto de slots de forma exclusiva. Para cada clave (key), Redis calculará qué slot le corresponde en función del nombre de dicha clave. Como cada slot tiene asociado un Shard, Redis sabrá donde debe almacenarlo o de dónde debe recuperar. Una librería cluster-aware será capaz de conectarse automáticamente al servidor Redis correcto para ejecutar la acción correspondiente (ej: GET, SET, etc.) de forma automática y transparente. Aún así, nos podemos encontrar con algunas limitaciones en Redis Cluster con comandos que actúan sobre diferentes slots.
Para más info:
- Redis Enterprise Cluster Architecture
- Clustering in Redis
- Redis Cluster and Client Libraries
- Redis Clustering Best Practices with Multiple Keys
Vamos a ver todo esto de una forma más práctica, con un laboratorio.
Creación de un Redis Cluster
Para poder crear un Redis Cluster, primero debemos arrancar un conjunto de instancias de Redis en modo Cluster (en este ejemplo vamos a crear seis Redis que formarán tres Shards o Node Groups), para lo cual, podríamos utilizar un fichero de configuración similar al siguiente para cada Redis, cambiando el puerto para cada instancia de Redis, donde destacar:
- La opción cluster-config-file especifica el fichero que almacenará la configuración del nodo.
- La opción cluster-node-timeout especifica el tiempo en milisegundos que un nodo debe estar indisponible para considerarse en fallo.
# redis-7000.conf
port 7000
pidfile /run/redis/redis-server-7000.pid
logfile /var/log/redis/redis-server-7000.log
dbfilename dump-7000.rdb
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-node-timeout 5000
appendonly yes
appendfilename "appendonly-7000.aof"Arrancaremos los seis Redis.
sudo /usr/bin/redis-server ./redis-7000.conf &
sudo /usr/bin/redis-server ./redis-7001.conf &
sudo /usr/bin/redis-server ./redis-7002.conf &
sudo /usr/bin/redis-server ./redis-7003.conf &
sudo /usr/bin/redis-server ./redis-7004.conf &
sudo /usr/bin/redis-server ./redis-7005.conf &Ahora que ya están arrancados los seis Redis, vamos a crear un Redis Cluster y unir los Redis a dicho Cluster, especificando que deseamos sólo una Réplica (para Producción utilizaríamos dos réplicas, de forma ideal). Con esto conseguiremos tener tres Shards o Nodo Groups, cada uno formado por un primario o master y una réplica, y los 16384 slots se repartiran entre estos tres Shards.
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1A continuación se muestra la salida de ejecución del comando anterior.
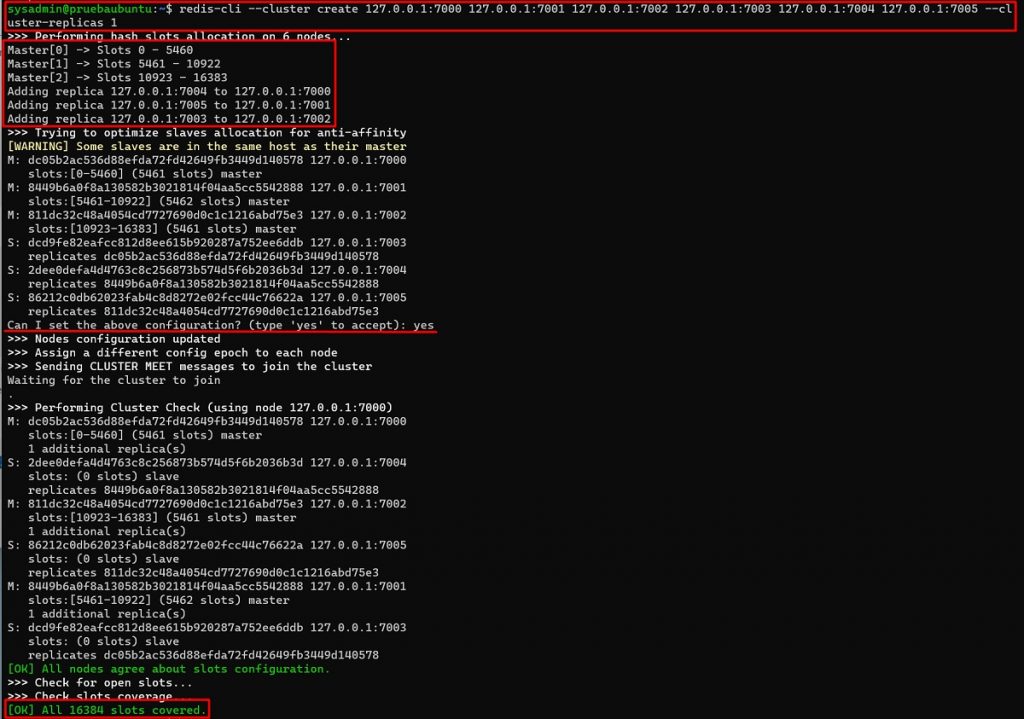
Importante tener en cuenta que Redis Cluster exige un mínimo de tres Shards (tres maestros), por lo que si intentamos ejecutar el anterior comando indicando 2 réplicas, obtendremos el siguiente error.

Conectarse a un Redis Cluster
Para conectarnos a un Redis Cluster utilizando redis-cli, deberemos conectarnos a cualquiera de los nodos especificando la opción –cluster ó -c, y de este modo cuando ejecutemos un comando (ej: SET, GET, etc), se re-conectará de forma automática al nodo que corresponda si lo necesita, aunque algunos comandos como KEYS tiene un alcance local al nodo en el que se ejecutan y necesitaremos ejecutarlo sobre todos los nodos utilizando CALL.
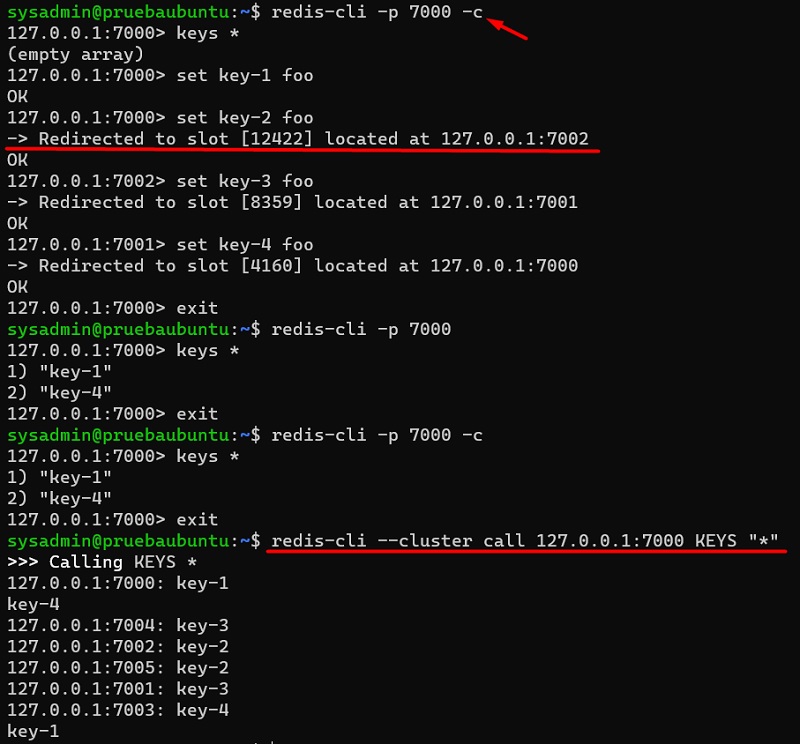
El tema, es que si nos conectamos a un nodo en concreto con redis-cli, sin la opción de cluster, sólo tendremos visibilidad sobre las claves que hay en dicho nodo (no veremos el resto de claves, que están distribuidas entre el resto de nodos), y si intentamos acceder a una clave que está en otro nodo, recibiremos un mensaje de error de tipo MOVED.
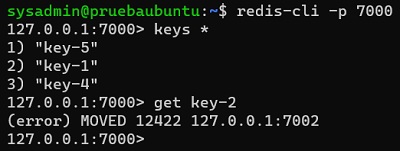
Podemos comprobar los nodos existentes del Cluster y su estado, con el comando CLUSTER NODES, como se muestra en el siguiente ejemplo, en el que una de las réplicas está caída (desconectada).

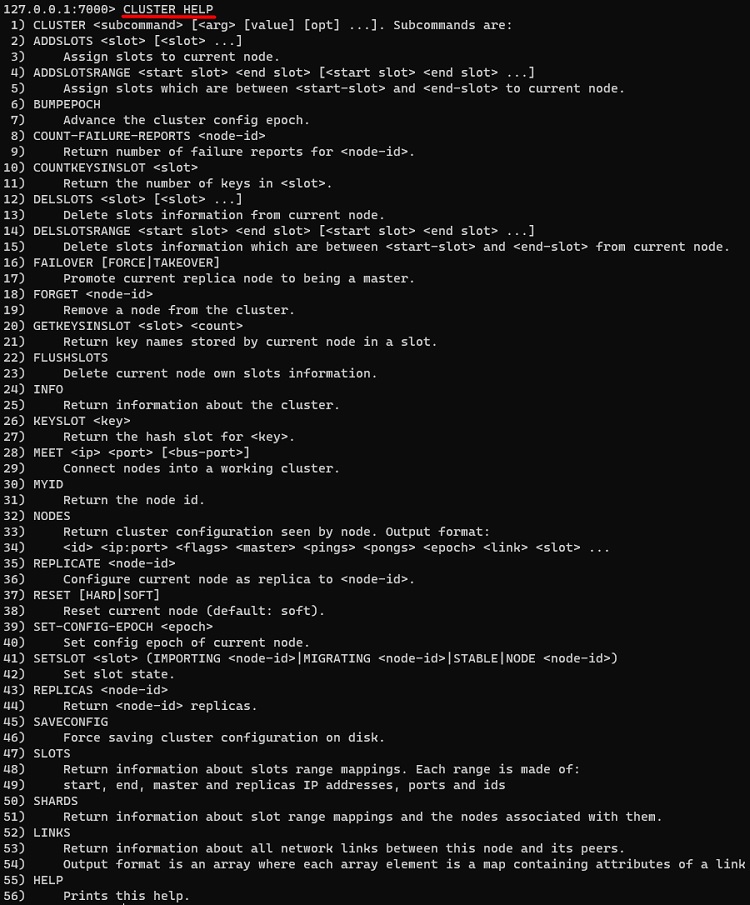
Otro comando útil es el comando CLUSTER HELP que nos mostrará ayuda sobre los diferentes subcomandos del comando CLUSTER.
Failover en un Redis Cluster
Vamos ahora a probar el Failover en nuestro pequeño Redis Cluster de laboratorio. Para este ejercicio vamos comprobar los nodos de nuestro Cluster, pararemos de forma ordenada uno de los maestros, comprobaremos de nuevo el estado de los nodos de nuestro cluster para ver que su esclavo ha sido promocionado a maestro, arrancaremos de nuevo el antiguo maestro, y volveremos a comprobar el estado de todos los nodos del Cluster (en maestro que paramos volverá a estar disponible, aunque ahora con el rol de esclavo). Esto lo podríamos resumir en los siguientes comandos.
redis-cli -p 7001 cluster nodes
redis-cli -p 7000 shutdown
redis-cli -p 7001 cluster nodes
sudo /usr/bin/redis-server ./redis-7000.conf &
redis-cli -p 7001 cluster nodesA continuación de muestra la salida de ejecución de los anteriores comandos, donde paramos de forma ordenada (comando SHUTDOWN) la instancia maestro que usa el puerto tcp-7000 y vemos como su esclavo (la tcp-7004) promociona automáticamente a maestro para garantizar el servicio. Al volver a arrancar la instancia, se mantiene subordinada como esclavo, y la tcp-7004 mantiene su nuevo rol de maestro.

Escalado Horizontal: Añadir Shards a un Redis Cluster existente
Vamos a probar a añadir un nuevo Shard (en nuestro caso, dos servidores, un primario con su réplica) a nuestro Redis Cluster, para así ver cómo podemos escalar horizontalmente nuestro Cluster para dotarle de más memoria (y también de más CPU). De forma similar a como hicimos antes, vamos a crear dos ficheros de configuración redis-7006.conf y redis-7007.conf utilizando los puertos tcp-7006 y tcp-7007 respectivamente, y vamos a arrancar esas dos nuevas intancias de Redis en modo Cluster.
sudo /usr/bin/redis-server ./redis-7006.conf &
sudo /usr/bin/redis-server ./redis-7007.conf &Seguidamente vamos a añadir la primera instancia (7006) al Cluster, como un nuevo nodo primario o master, tras lo cual, ejecutaremos el comando CLUSTER NODES para comprobar que ya ha sido añadido y anotar el ID del nuevo nodo, que es un dato que necesitaremos después para añadir su réplica. Lo haremos con los siguientes comandos.
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000
redis-cli -p 7000 cluster nodesA continuación se muestra la ejecución de los comandos anteriores.
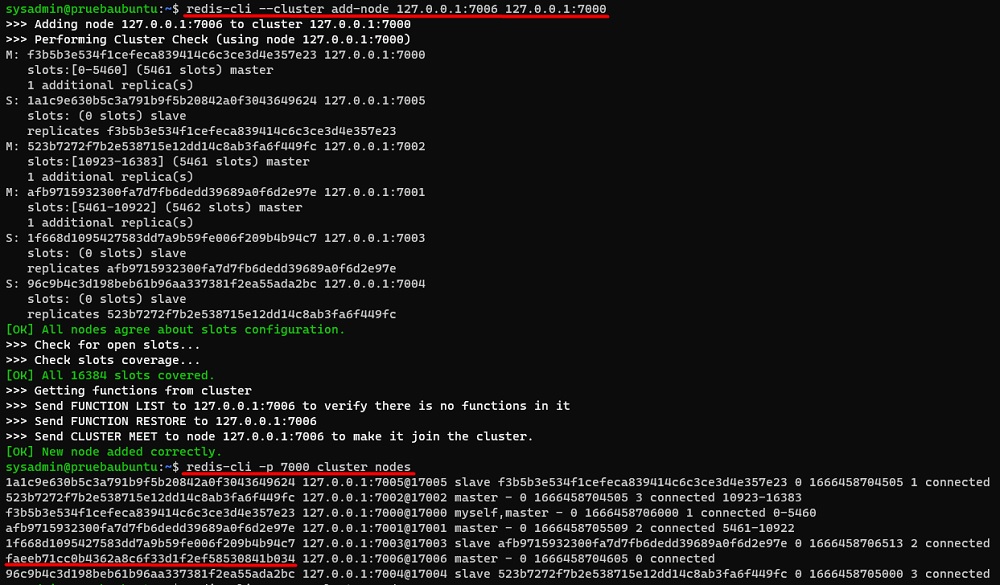
Ahora vamos a añadir la segunda instancia (7007) al Cluster, como una réplica (slave) del nodo anterior (tendremos que especificar el ID del nodo master al que nos uniremos como réplica), tras lo cual, ejecutaremos el comando CLUSTER NODES para comprobar que ya ha sido añadido, y comprobar el estado de ambos nodos.
redis-cli -p 7000 --cluster add-node 127.0.0.1:7007 127.0.0.1:7000 --cluster-slave --cluster-master-id faeeb71cc0b4362a8c6f33d1f2ef58530841b034
redis-cli -p 7000 cluster nodesA continuación se muestra la ejecución de los comandos anteriores.
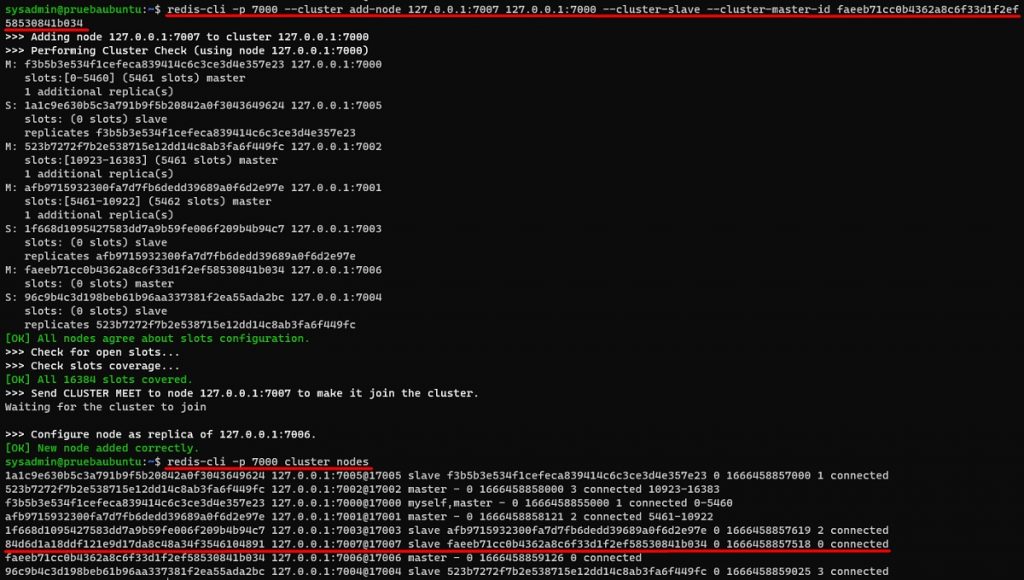
Realizado todo esto, nuestro Redis Cluster ya tiene ocho nodos (cuatro Shards), cuatro actuando como primarios o masters, y otros cuatro actuando como réplica de los anteriores. Sin embargo, el nuevo Shard formado por los dos nuevos nodos (primario y réplica) aún están vacíos y no tienen asignado ningún slot (no almacenan ninguna clave), algo que podemos comprobar fácilmente con el comando CLUSTER SLOTS. Para solucionarlo tendremos que realizar un RESHARD del Cluster, que nos permita mover slots de los nodos primarios originales, al nuevo nodo primario que acabamos de añadir al cluster, para así poder repartir las claves entre todos los Shards del Cluster. Para poder hacer el RESHARD necesitamos especificar:
- El numero de slots a mover. Dado que tenemos un total de 16384 slots, especificaremos 4096, para poder repartir los slots por igual entre los cuatro primarios.
- El ID del nodo que recibirá los slots, es decir, el ID del nuevo nodo primario que acabamos de añadir.
- Los nodos desde donde deseamos mover los slots. En este caso, especificaremos all, para poder repartir los slots por igual entre los cuatro primarios.
redis-cli -p 7000 --cluster reshard 127.0.0.1:7000A continuación se muestra la ejecución del comando anterior.
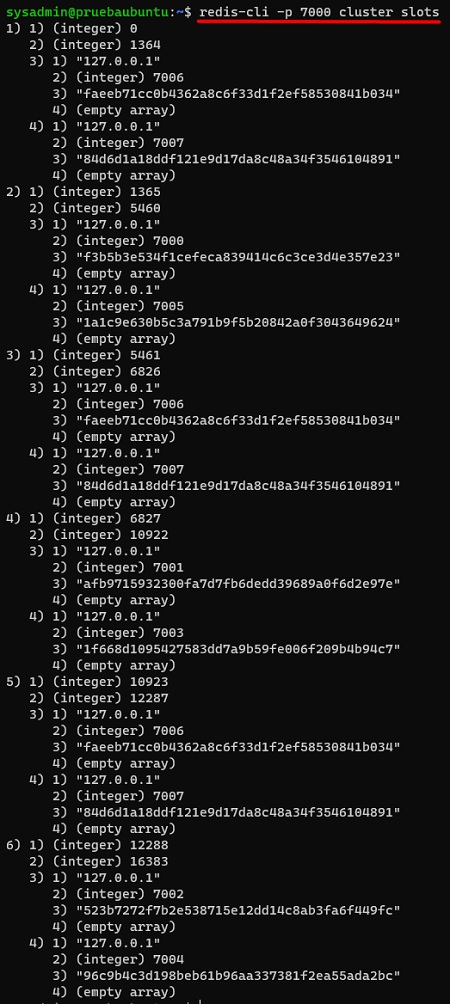
Con esto ya hemos acabado de escalar nuestro Redis Cluster, pudiendo ejecutar el comando CLUSTER SLOTS para comprobar como han quedado ahora repartidos los slots entre todos los Shards y sus nodos.
Redis en Cloud de Azure
Redis mola, pero también es cierto que cuando empiezas a trabajar con Replicación, Sentinel, y especialmente con Redis Cluster, empieza a ponerse la cosa entretenida, y eso en ocasiones puede llegar convertirse en una distracción para cumplir nuestros objetivos de negocio en tiempo y forma. Esa es la ventaja de las soluciones Cloud de Redis, minimizar su esfuerzo de mantenimiento.
Podemos utilizar Redis Cloud, la solución Cloud del propio fabricante basada en Redis Enterprise: Redis Cloud – Pricing
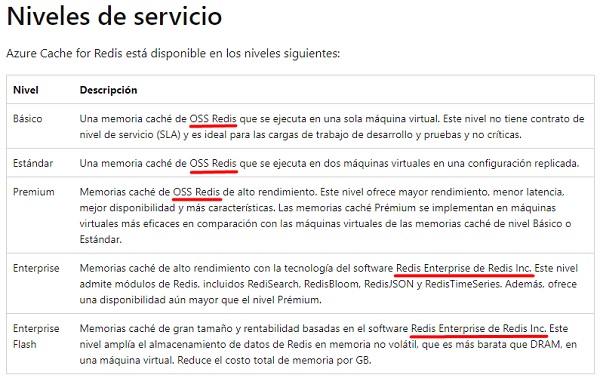
En Azure tenemos soluciones ofrecidas por Microsoft (niveles básicos, estándar y premium, que usan OSS Redis) y soluciones ofrecidas por el propio Redis (niveles Enterprise y Enterprise Flash, que usan Redis Enterprise), teniendo en cuenta que:
- Redis Estándar utiliza Replicación
- Redis Premium utiliza Replicación, y opcionalmente podemos utilizar Redis Cluster si lo deseamos.
- Redis Enterprise y Redis Enterprise Flash, utilizan Redis Cluster.
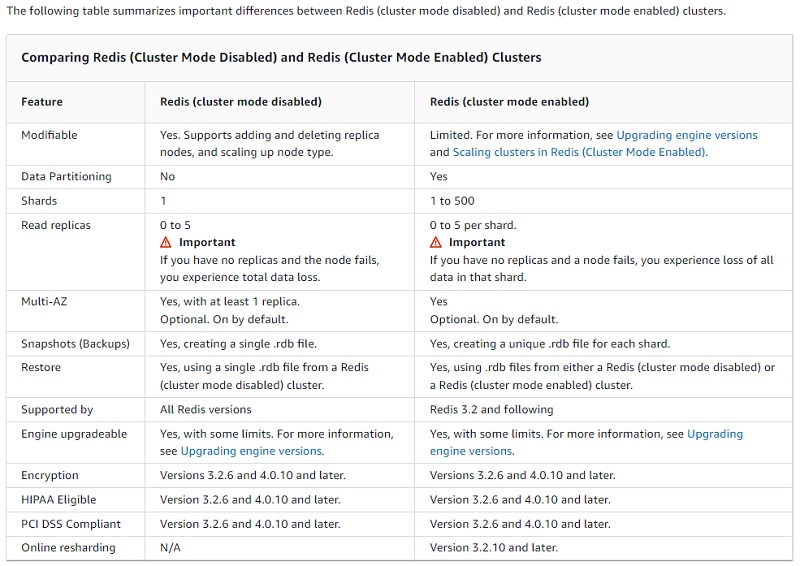
AWS ofrece MemoryDB for Redis y ElasticCache for Redis, siendo más habitual el segundo, que permite configuraciones basadas en Replicación y en Redis Cluster, como se muestra en la siguiente tabla comparativa. Además es bastante más avanzado y económico que su alternativa en Azure (ej: más libertad y control de la versión de Redis, ofrece endpoints para acceso de lectura a las réplicas, más opciones de sizing de VMs para optimizar precio y/o rendimiento, mayor libertad de configuración de muchos aspectos como el reparto de slots entre Shards, etc).
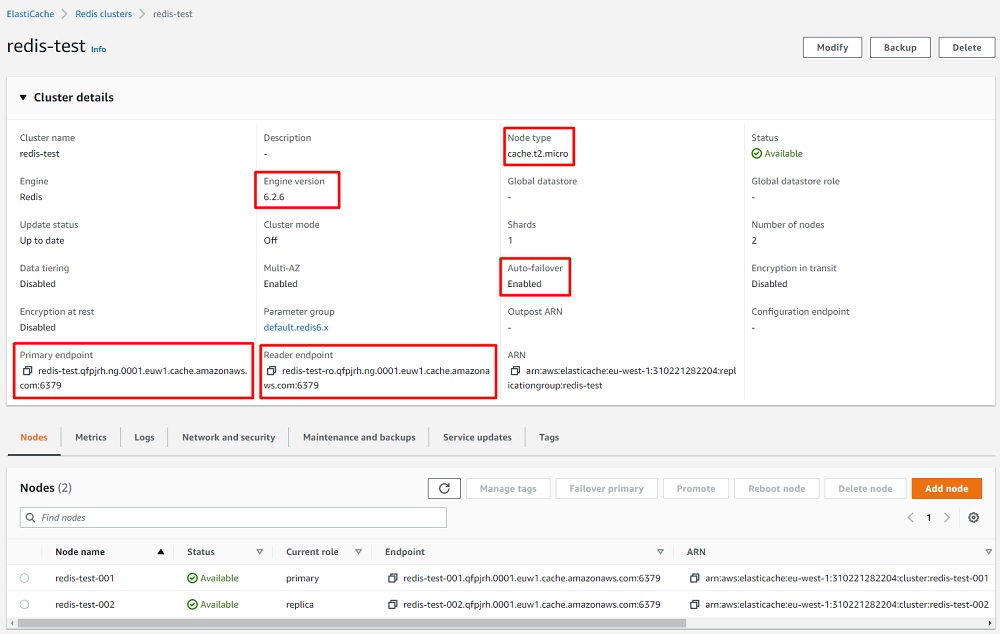
A continuación se muestra un ejemplo en AWS, con un único Shard, un tamaño pequeño y económico de máquina, endpoints de escritura y de lectura, etc.
Despedida y Cierre
Hasta aquí llega este Post, en el que hemos intentado explicar en qué consiste un Redis Cluster, sus conceptos (ej: Slots, Shards, etc.) y cómo aporta escalabilidad horizontal (scaling out) mediate el reparto del espacio de claves entre slots, que son repartidos entre los diferentes Shards, cada uno de los cuales puede estar formado por un primario y ninguna, una o varias Réplicas. Esto permite que cada servidor almacene y se responsabilice de sólo una parte de los slots (y por lo tanto de las claves), permitiendo el crecimiento a base de añadir más nodos al Redis Cluster. Una alternativa muy interesante, disponible en la versión Open Source de Redis, con el inconveniente de que sólo permite el uso de db0, aumenta el esfuerzo de mantenimiento de Redis (se agradece mucho las soluciones Cloud, que te abstrante de todos estos quebraderos de cabeza), algunas limitaciones al trabajar con claves que pertenecen a diferentes slots, y que al igual que ocurría con Sentinel, tendremos que utilizar una librería cluster-aware y cambiar la forma de conectarnos a Redis.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.