
El AlertManager es un gestor de Alertas para clientes como Prometheus (expone endpoints REST), capaz de agruparlas, inhibirlas, silenciarlas (si aplica), enrutarlas, y de notificar a través de diferentes medios como Slack, mail (SMTP), OpsGenie, WeChat, Telegram, un WebHook, un busca (PagerDuty), etc.
Continuando con nuestra serie sobre Prometheus, ahora que ya hemos explicado qué es Prometheus y cómo instalarlo en una Raspberry (o en Ubuntu), así como del Node Exporter, el Blackbox Exporter, y Grafana como herramienta de visualización para Prometheus, ahora toca el turno de otra de las principales piezas de Prometheus: AlertManager
Introducción a AlertManager
Prometheus es capaz de generar alertas en base a la evaluación de una expresión PromQL, que en caso de cumplirse durante un valor determinado (mientras no ha pasado suficiente tiempo, se mantendrán en estado Pending), las enviará a un AlertManager, para que se procesen y se notifique al personal adecuado.
El AlertManager es el servidor de alertas del stack de Prometheus, que utiliza su propio fichero de configuración y se ejecuta como un proceso independiente del propio Prometheus Server, que se encarga de la gestión de las notificaciones de las alertas, que podemos instalar en el mismo o en diferente servidor. De hecho, podemos tener varios Prometheus Server enviando alertas a un mismo AlertManager, para que las gestione y notifique. Es decir:
- Prometheus recolecta la información (métricas) de los diferentes recursos monitorizados, así como define la alertas (alert rules) como una expresión PromQL que se mantiene durante un determinado periodo de tiempo, y se las envía al AlertManager. Además, en la definición de las alertas:
- Es posible añadir nuevas etiquetas (labels) que proporcionen información adicional al operador o técnico que las atienda. Un ejemplo habitual sería la etiqueta severity, que puede tener valores como critical, major, warning, info, etc. o la etiqueta env, que puede tener valores como production, test, develop, etc.
- Es posible añadir anotaciones, que proporcionen información adicional más extendida que la que proporcionan las etiquetas, como podría ser summary, description,
- AlertManager gestiona las notificaciones de las alertas.
Cuando la expresión PromQL de una alerta no se cumple, está en estado Inactive. Cuando comienza a cumplirse su expresión PromQL, pasa a estado Pending, en el que se mantendrá durante el periodo de tiempo que definamos para la alerta, pasado el cual, pasará a estado Firing.
Los principales conceptos de AlertManager son los siguientes:
- Rutas (routes) y Receptores (receivers). Son el corazón de la configuración de AlertManager. Determinan los caminos que pueden seguir las alertas y las acciones asociadas, pudiendo crear una jerarquía de rutas y sub-rutas (sólo aplicarían sobre un subconjunto de las alertas de la ruta padre, pudiendo utilizar el atributo continue para permitir evaluar rutas hermanas aún en caso de match). Cada ruta está asociada a receptores (receivers), que son los destinatarios de las notificaciones (ej: un canal de Slack, una dirección de correo electrónico, etc). Se configura en el fichero de configuración de AlertManager.
- Agrupamiento (grouping). Permite agrupar alertar similares en una única notificación, útil en una gran indisponibilidad afectando múltiples dispositivos, evitando spam.
- Inhibición (Inhibition). Permite definir dependencias entre servicios, de tal modo que sea posible eliminar notificaciones de alertas dependientes, si la alerta de la cual depende se ha producido. Por ejemplo, si una base de datos está indisponible, no sería necesario notificar también por las alertas de las aplicaciones dependientes de la misma. Se configura en el fichero de configuración de AlertManager.
- Silenciamiento (Silences). Permite deshabilitar notificaciones temporalmente para un determinado conjunto de alerts, mediante su configuración desde la interfaz Web de AlertManager. Resulta de gran utilidad. Por ejemplo, si estamos realizando una intervención planificada en Producción, podemos sinlenciar las alertas relacionadas con dicha intervención durante la duración de la misma (ventana de mantenimiento). Igualmente si tenemos una incidencia de larga duración, que ya tenemos localizada y sobre la que estamos trabajando, podemos silenciar las alertas relacionadas hasta la resolución de la misma.
Además del binario del propio AlertManager, también tenemos el binario amtool, que permite ver y modificar el estado del AlertManager desde línea de comando. Por ejemplo, con amtool podemos silenciar alertas, expirar el silenciado, importar silenciado de alertas, consultar el silenciado de aletas, etc.
Es posible configurar AlertManager en Alta Disponibilidad (HA), funcionando en modo at-least-once-delivery, de tal forma que:
- Prometheus enviará las alertas a todas las intancias del Cluster de AlertManager.
- Las instancias de AlertManager se comunicarán entre si para conocer el estado de las mismas.
- Si todas las intancias de AlertManager están OK, sólo la primera enviará las notificaciones.
- Sólo en caso de que quedaran aisladas a nivel de red, se podría producir múltiples notificaciones para la misma alerta.
Algunos enlaces de interés antes, de continuar:
- La documentación de definición de alertas (alert rules): Prometheus – Alerting Rules
- La documentación de AlertManager: Prometheus – AlertManager
- Repo GitHub de AlertManager: GitHub – Prometheus – AlertManager
- La documentación de la API de AlertManager: Prometheus – AlertManager OpenAPI
- Documentación de amtool: Debian – Prometheus AlertManager – amtool
Instalación de AlertManager
A continuación vamos a comenzar con la instalación del AlertManager. En nuestro caso de ejemplo, vamos a hacerlo en una Raspberry (sería igual en Ubuntu, salvo el binario que tenemos que instalar), y vamos a instalar AlertManager en el mismo servidor que ejecuta el servidor Prometheus.
Lo primero, actualizamos el sistema operativo, instalamos algunas utilidades (wget, gurl, y vim), y creamos un grupo y un usuario (que no permite login) para Prometheus (si no lo hemos hecho antes, por ejemplo, si es la misma máquina en la que antes instalamos Prometheus u otro Exporter, ya estarían creados), con la intención de evitar que el demonio del AlertManager se ejecute con un superusuario como root (por motivos de seguridad).
sudo apt update -y && sudo apt upgrade
sudo apt -y install wget curl vim
sudo groupadd --system prometheus
sudo useradd -s /sbin/nologin --system --no-create-home -g prometheus prometheusDescargamos la última versión del AlertManager para Raspberry (armv7) sobre un directorio temporal (Prometheus – Download), lo descomprimimos, movemos los binarios a /usr/local/bin (así lo podemos ejecutar sin añadir nada al PATH), creamos un directorio /etc/alertmanager para almacenar su fichero de configuración, y lo movemos a dicho directorio. También cambiamos el propietario del binario y fichero de configuración, por motivos de seguridad. Por último creamos un directorio para los datos de AlertManager y le cambiamos el propietario.
NOTA: Si se deseas instalar el AlertManager en Ubuntu, en lugar de filtrar por linux-armv7 (Raspberry Pi 2, 3, 4) bastaría con filtrar por linux-amd64 en el siguiente comando, y ya está. El resto de las instrucciones indicadas en este Post serían válidas.
curl -s https://api.github.com/repos/prometheus/alertmanager/releases/latest | grep browser_download_url | grep linux-armv7 | cut -d '"' -f 4 | wget -qi -
tar xvf alertmanager-*.tar.gz
cd alertmanager*/
sudo mv alertmanager /usr/local/bin/
sudo mv amtool /usr/local/bin/
sudo mkdir /etc/alertmanager
sudo mv alertmanager.yml /etc/alertmanager
sudo chown root:root /etc/alertmanager/alertmanager.yml
sudo chown root:root /usr/local/bin/alertmanager
sudo chown root:root /usr/local/bin/amtool
sudo mkdir /var/lib/alertmanager
sudo chown prometheus:prometheus /var/lib/alertmanagerRealizado esto podemos ejecutar el siguiente comando para comprobar la versión instalada de AlertManager:
alertmanager --version
Aprovechamos un momento para revisar el fichero de configuración del AlertManager que incluye por defecto, que viene con una configuración básica, que podemos ir completando y cambiar conforme a nuestras necesidades. Para ello ejecutaremos un comando como el siguiente:
cat /etc/alertmanager/alertmanager.yml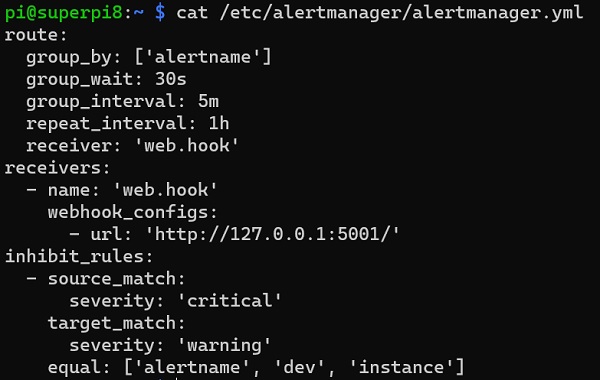
Para poder manejar el AlertManager como un servicio o demonio, vamos a crear su fichero de configuración de systemd, que ejecute el binario con el fichero de configuración que queremos como parámetro y apunte al directorio de datos de AlertManager.
sudo tee /etc/systemd/system/alertmanager.service<<EOF
[Unit]
Description=Prometheus AlertManager
Documentation=https://github.com/prometheus/alertmanager
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
User=prometheus
Group=prometheus
ExecReload=/bin/kill -HUP $MAINPID
ExecStart=/usr/local/bin/alertmanager \
--config.file=/etc/alertmanager/alertmanager.yml \
--storage.path=/var/lib/alertmanager/ \
--web.listen-address=":9093"
--cluster.listen-address=
[Install]
WantedBy=multi-user.target
EOFHecho esto, activamos y arrancamos el servicio de AlertManager (así queda configurado para arrancar automáticamente con el inicio del sistema):
sudo systemctl daemon-reload
sudo systemctl start alertmanager
sudo systemctl enable alertmanager
sudo systemctl status alertmanager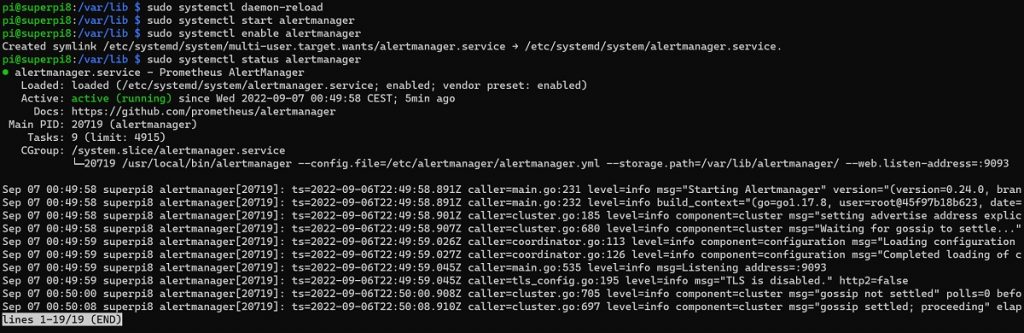
Realizado esto, si accedemos al puerto 9093 a través de un navegador, podremos acceder a la interfaz Web de AlertManager.

Para continuar, necesitamos monitorizar nuestro AlertManager con nuestro servidor Prometheus. Para ello, nos conectamos al servidor Prometheus por SSH y editamos el fichero de configuración de Prometheus, en nuestro caso, con un comando como este:
sudo vi /etc/prometheus/prometheus.ymlAñadiremos el target correspondiente al AlertManager dentro de la sección scrape_configs, para que de este modo podamos monitorizar el AlertManager con Prometheus.
# AlertManager
- job_name: alertmanager
static_configs:
- targets: ["localhost:9093"]Además, en la sección alerting añadiremos los datos de conexión al AlertManager, para que Prometheus envíe sus alertas al AlertManager. En nuestro caso de ejemplo, al haberlo instalado en el mismo servidor que Prometheus, usaremos localhost.
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]Comprobaremos que el fichero de configuración es válido (con promtool) y tras comprobar que está OK, refrescamos la configuración de Prometheus con un killall.
promtool check config /etc/prometheus/prometheus.yml
sudo killall -HUP prometheusRealizado esto, podremos comprobar en Prometheus, que pasados unos segundos ya empieza a obtener las métricas del nuevo Job que hemos configurado para el AlertManager.

Ya tendríamos AlertManager instalado, y con una configuración básica. Pero esto sólo acaba de comenzar 🙂
Configuración de nuestra primera Alerta en Prometheus
Las reglas de alertas (alert rules) las configuraremos en Prometheus (en forma de expresiones PromQL), no en el AlertManager (en el que delegaremos la acción o notificación). Por lo tanto, será Prometheus el encargado de evaluar las alertas de forma periódica (ej: cada 15s), y enviarlas al AlertManager, para su notificación.
Podemos tener varios ficheros de definición de alertas (alert rules), que almacenarmos en /etc/prometheus/rules y de este modo, según va creciendo nuestra infraestructura, podemos tener bien organizada toda esta configuración entre diferentes ficheros, incluso si tenemos varios servidors Prometheus, podemos reutilizar los ficheros de alertas entre ellos. Para nuestro ejemplo, vamos a utilizar un único fichero rules.yml, que editaremos con el siguiente comando:
sudo vi /etc/prometheus/rules/rules.ymlA continuación se muestra el contenido que utilizaremos para nuestro ejemplo, que levantará una alerta para cualquier Node Exporter que se encuentre caído durante al menos 5 min. por el motivo que sea (ej: máquina apagada, servicio detenido, aislamiento a nivel de red, etc.), especificando la alerta como crítica:
groups:
- name: test
rules:
- alert: InstanceDown
expr: up{job="node_exporter"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."Una vez tenemos nuestro fichero de definición de alertas (alert rules), podemos comprobar que el fichero es correcto, utilizando un comando promtool como el siguiente:
promtool check rules /etc/prometheus/rules/rules.ymlHecho esto, vamos a editar el fichero de configuración de Prometheus.
sudo vi /etc/prometheus/prometheus.ymlEn el fichero de configuración de Prometheus, añadiremos el fichero de definición de alertas que acabamos de crear, y guardaremos los cambios.
...
rule_files:
- rules/rules.yml
...Comprobaremos que el fichero de configuración es válido (con promtool) y tras comprobar que está OK, refrescamos la configuración de Prometheus con un killall.
promtool check config /etc/prometheus/prometheus.yml
sudo killall -HUP prometheusRealizado esto podremos comprobar la definición de la alerta en la interfaz Web de Prometheus (Status -> Rules).
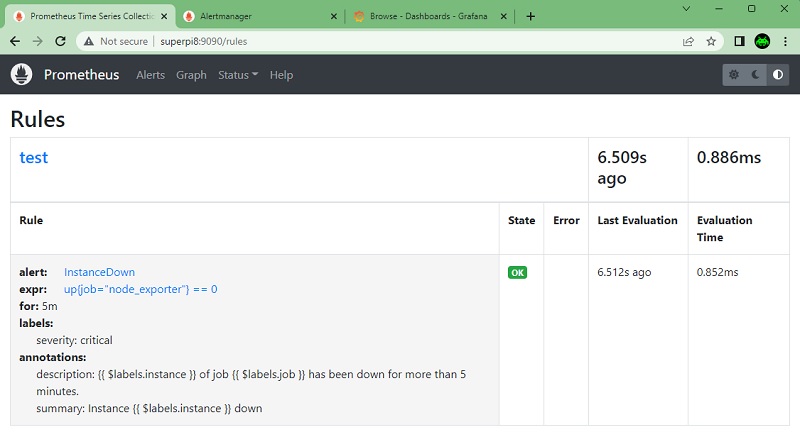
También podemos comprobar la definición y estado de las alertas en la interfez de Prometheus, desde la opción Alerts, como se muestra a continuación.
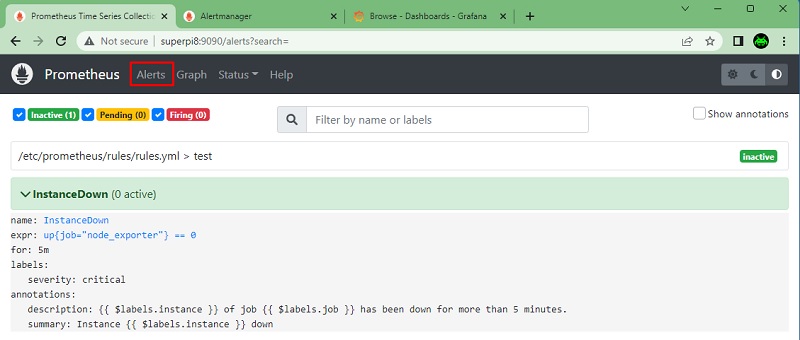
Configurar la notificación con AlertManager a través de Gmail
Para poder configurar Gmail como un receiver de AlertManager, deberemos crear en nuestra cuenta de Gmail una App Password, que a su vez requiere que configuremos en nuestra cuenta de Google la autenticación de doble factor.

Editaremos el fichero de configuración del AlertManager, para configurar el receptor (receiver) para Gmail.
sudo vi /etc/alertmanager/alertmanager.ymlAñadiremos una configuración similar a la siguiente, con los datos de nuestra cuenta de Gmail y nuestra App Password, y especificaremos que queremos utilizar dicho receptor (receiver) de gmail.
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'operator-team'
receivers:
- name: 'operator-team'
email_configs:
- to: '<google-username>@gmail.com'
from: '<google-username>@gmail.com'
smarthost: smtp.gmail.com:587
auth_username: '<google-username>@gmail.com'
auth_identity: '<google-username>@gmail.com'
auth_password: '<google-app-password>'
...Otra forma alternativa de hacerlo sería la siguiente, en la que utilizamos una configuración global, y además especificamos dos métodos de notificación para un mismo receptor (receiver):
global:
smtp_smarthost: smtp.gmail.com:587
smtp_from: '<google-username>@gmail.com'
smtp_require_tls: true
smtp_hello: 'alertmanager'
smtp_auth_username: '<google-username>@gmail.com'
smtp_auth_password: '<google-app-password>'
slack_api_url: 'https://hooks.slack.com/services/x/yy/zzz'
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'operator-team'
receivers:
- name: 'operator-team'
email_configs:
- to: '<google-username>@gmail.com'
slack_configs:
# https://prometheus.io/docs/alerting/configuration/#slack_config
- channel: 'system_events'
- username: 'AlertManager'
- icon_emoji: ':joy:'
...Guardaremos los cambios, y los aplicaremos en el AlertManager.
sudo killall -HUP alertmanagerHecho esto, ya sólo nos quedará esperar a que se produzca una alerta (o forzarla nosotros, por ejemplo, parando el servicio Node Exporter de una de la máquinas monitorizadas), para que recibir la correspondiente notificación.
Si necesitamos depurar el envío de notificaciones de AlertManager, podemos utilizar un comando como el siguiente, para ver los logs del AlertManager.
sudo journalctl --follow --no-pager --boot --unit alertmanager.serviceEjemplos de Alertas en Prometheus
Podemos definir diferentes tipos de reglas de alertas (alert rules) para medir diferentes aspectos de nuestra infraestructura. Los siguientes son ejemplos para medir indisponibilidad.
- Indisponibilidad de los Node Exporters:
up{job="node_exporter"} == 0 - Indisponibilidad de HTTP:
probe_success{job="blackbox_exporter_http"} == 0
Otros ejemplos de alertas para medir consumo de recursos, serían las siguientes:
- Espacio en disco de particiones EXT4 de los Node Exporters por debajo del 10% de espacio libre:
node_filesystem_free_bytes{fstype="ext4",job="node_exporter"} / node_filesystem_size_bytes{job="node_exporter"} * 100 < 10 - Memoria libre de los Node Exporters por debajo del 10%:
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10 - Load Average, teniendo en cuenta el número de cores:
node_load5 / count by (instance, job) (node_cpu_seconds_total{mode="idle"}) >= 0.8 - Código de estado HTTP:
probe_http_status_code <= 199 OR probe_http_status_code >= 400 - Certificados SSL para HTTPS que van a expirar en menos de 20 días:
3 <= round((last_over_time(probe_ssl_earliest_cert_expiry[10m]) - time()) / 86400, 0.1) < 20
Este sería un fichero de definición de alertas más completo, a modo de ejemplo:
groups:
- name: test
rules:
- alert: NodeExporterDown
expr: up{job="node_exporter"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
- alert: NodeExporterFreeDiskSpace
expr: node_filesystem_free_bytes{fstype="ext4",job="node_exporter"} / node_filesystem_size_bytes{job="node_exporter"} * 100 < 10
for: 5m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} free disk space is very low"
description: "Device {{ $labels.device }} of {{ $labels.instance }} of job {{ $labels.job }} is about to run out of disk space."
- alert: NodeExporterFreeMem
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 8
for: 5m
labels:
severity: major
annotations:
summary: "Instance {{ $labels.instance }} free mem is very low"
description: "{{ $labels.instance }} of job {{ $labels.job }} is about tu run out of disk space."
- alert: NodeExporterLoadAverage
expr: node_load5 / count by (instance, job) (node_cpu_seconds_total{mode="idle"}) >= 0.8
for: 5m
labels:
severity: major
annotations:
summary: "Instance {{ $labels.instance }} load average is very high"
description: "{{ $labels.instance }} of job {{ $labels.job }} load average is very high."
- alert: WebSiteDown
expr: probe_success{job="blackbox_exporter_http"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Web Site {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
- alert: WebSiteHttpStatus
expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400
for: 5m
labels:
severity: critical
annotations:
summary: "Web Site HTTP Status failure for {{ $labels.instance }}"
description: "HTTP Status code is not 200-399 for {{ $labels.instance }}."
- alert: CertificateWillExpireSoon
expr: 3 <= round((last_over_time(probe_ssl_earliest_cert_expiry[10m]) - time()) / 86400, 0.1) < 20
for: 0m
labels:
severity: warning
annotations:
summary: "SSL certificate will expire soon for {{ $labels.instance }}"
description: "SSL certificate expires in less than 20 days for {{ $labels.instance }}."Igual que estos ejemplos, buscando en Internet podemos encontar mucho más, la siguiente página incluye bastante ejemplos: Awesome Prometheus alerts
Algunos de los ejemplos anteriores los puedes descargar del siguiente enlace: prometheus-alert-rules.zip
Importar Dashboards en Grafana
De las últimas cosas que nos quedan, es aprovechar para importar algún Dashboard en Grafana que nos muestre información sobre nuestras Alertas y Notificaciones. Los más conocidos son los siguientes:
- AlertManager (ID 9578). Utiliza un Datasource de tipo Prometheus.
- Prometheus AlertManager (ID 8010). Utiliza un Datasource de tipo AlertManager, pero no funciona con las versiones más recientes.
Despedida y Cierre
Con todos estos pasos, hemos visto cómo instalar y configurar AlertManager y usarlo en las notificaciones de Alertas de Prometheus, incluyendo detalles como la configuración de notificaciones por mail a través de Gmail, definición de alertas (alert rules), importación de algún Dashboard existente de Grafana, etc.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.